
点赞,中国速度!
从跟跑到领跑,在新一期全球超级计算机500强榜单中,中国超算高调夺取冠亚军,中国速度举世瞩目!然而全面反超也带来了一片质疑声音,包括中国超算专家也在呼吁,回归HPC初心,发展超算不能脱离应用。秉承“在中国,为中国”理念,戴尔HPC助力超算在中国的行业应用更具广度和深度, 也为在路上的中国超算,带来更多的成功实践,助力中国速度升级中国力量!

提到HPC产业发展,总让人感觉酣畅淋漓,又意犹未尽……每年的6月和11月,都有HPC产业的盛会,也会揭晓新一轮的超算TOP500榜单。
尤其这次第50届榜单中,中国以大幅度的优势领先美国,成为国家份额中的第一名。于是,各种媒体、传播渠道的报道四处开花,提醒我们中国HPC已进入“大国速度”!
从“大国”到“强国”
中国超算在路上
从当年的曙光一号到后来的天河一号,再到曾经获得TOP500冠军的天河一号A、天河二号和神威·太湖之光,中国的超级计算机硬件水平已经实现了世界领先级别。可以说,具备搭建大型超算、具备搭建大型世界一流超算的能力,意味着中国已经步入了超算大国的行列。
可能还有很多人不理解大型超算的建造有多么困难——与大众想象中的“堆机器”不同,超算是一个相当复杂的系统,各个服务器、存储之间的互联互通和同步、延迟等问题都至关重要。就好比我们不能只凭一堆沙子、砖头、钢筋水泥就造出一栋大厦一样,建造超算系统是一项极其复杂的“技术活”。

更加困难的是如何将大型超算利用起来,这自然就涉及到软件、算法和应用程序。就如同早前,中科院超算中心主任迟学斌在接受媒体时直言不讳地指出:“脱离开发利用,超算就是一堆破铜烂铁。光有高性能机器,没有人才做高水平的服务,那效果是一样的,机器过5年就过时了。”
以我国近十年的超算数量增速来看,5年已经足够完成一个系列研发。然而凭借超算占有量和运算速度的数据还不够,中国已经迈向“超算强国”的道路,需要向更高一层面完成提升。

易构计算 x 全新互联
性能饕餮大师玩转超算应用
HPC这个“性能饕餮”对于计算力的渴求使得越来越多的企业需要为其提供专门的设备。这些设备不仅仅需要最先进的硬件与技术支持,还需要能够应对最热门的应用,比如针对图形图像分析的深度学习应用,再比如更为广泛的人工智能应用。

这也正是戴尔所擅长的领域。早在多年前,戴尔就曾专门为HPC行业应用推出了PowerEdge C系列的服务器,这个系列的产品或是具备超高的计算密度、或是具备超大的存储容量,又或者具备强大的扩展性能,支持更多的加速设备。总体说来,PowerEdge C系列就是瞄准HPC行业应用的痛点,进而推出了完善的解决方案。

加速器优化的全新计算节点PowerEdge C4140
我们今天要介绍的,就是其中一款名为PowerEdge C4140的产品。这款产品是戴尔为HPC解决方案所打造的第十代服务器产品,也凝聚了戴尔在HPC领域的技术积累。如果非要以一个词来概括PowerEdge C4140有什么亮点的话,那么我选择这四个字——异构计算。
异构计算,这在HPC领域并非是一个全新的概念。早在2009年,这个概念就已经在超算领域中被采纳。如今,异构计算已经成为了超算领域的主流模式,越来越多的超级计算机都在采用异构计算来提升计算力。
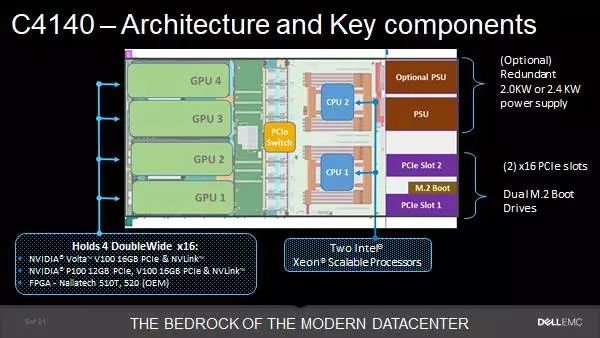
既然超算对于计算力有着无尽的渴求,既然异构计算能够大幅度提升计算力,那自然支持异构计算也是行业的大势所趋。本次戴尔推出的PowerEdge C4140恰恰就是为异构计算而生,它在1U的空间内最大提供了对于4块异构计算加速卡的支持,能够在这么狭小的空间内实现这么大的空间利用率,的确是非常难得。要知道,许多2U的主流双路服务器最多也只能支持2块加速卡。
在这里,我们还要明确一个概念,异构计算不等于GPU计算,但是目前几乎整个行业都在用NVIDIA的GPU进行异构计算,所以对于服务器厂商来说,支持GPU计算也是必然的选择。
作为最新产品,PowerEdge C4140可以支持Pascal架构的P100 GPU或者采用最新Volta架构的V100 GPU。后者是NVIDIA今年4月刚刚发布的新品,专为深度学习应用进行了优化。
当然对于PowerEdge C4140来说,在支持GPU加速的同时,它还能够支持NVIDIA特有的NVLink技术,这也是它区别于其他产品的关键所在。NVLink是一项基于CPU-GPU和GPU-GPU之间的超高速数据传输,它与传统传输最大的区别就是不需要借助于PCI-E总线的支持。
就目前来说,PCI-E总线依旧停留在3.0阶段,它所提供的最大带宽为32GB/s,而NVLink在实现直接通信之后,带宽可以达到160GB/s,是PCI-E总线的5倍。换句话说,在计算能力方面,具备NVLink技术的PowerEdge C4140相比其他竞品来说具备更为明显的优势。
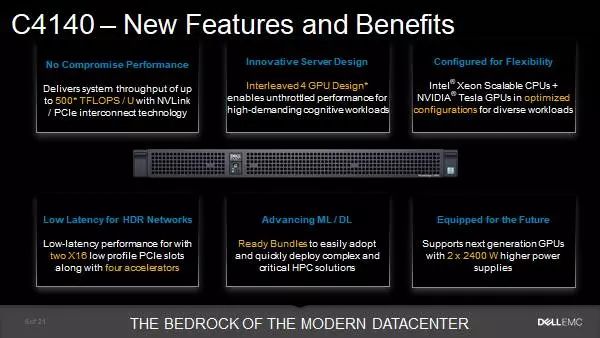
除了上述特性之外,在硬件的优化方面,PowerEdge C4140还具有两个PCIe x16插槽,支持Mellanox最新的200Gb/s HDR InfiniBand或者Intel Omni-Path 25GbE高速网络;用户可选2KW或者2.4KW冗余电源,是当前服务器中最高规格的电源设计,充分保证异构计算的能耗需求。
说过了硬件,我们再来看看应用。PowerEdge C4140主要面向三大领域——机器学习和深度学习;科学计算,包括科研、生命科学等;要求低延迟、高性能的场景,如金融分析等。在这些应用场景中,借助于全新的互联方式和异构计算带来的强大计算能力,借助于200Gb/s InfiniBand网络带来的高性能与低延迟,PowerEdge C4140可以为用户提供最佳应用体验,满足对计算力的渴求。
服务“思考型”客户
戴尔HPC赋予行业应用深度力量
如今,已经有许多科研机构和高校都在采用戴尔的HPC设备进行高性能计算。

- 在清华大学,戴尔提供了高性能集群HPC平台,承载和支撑大规模生物学、医学领域的研究计算任务:充分利用HPC平台海量数据处理和并行计算能力,为生物大数据的高效处理和分析提供创新机制,满足生命科学、生物学、医学和其他交叉科学不断提出的新要求和挑战;
- 在上海交大,戴尔HPC存储系统解决方案成功提升了上海交大科研和教学的竞争力:不仅成功应对了用户日益增长的存储要求,提升了存储系统性能的稳定性,并提供了轻松、高效、安全的管理环境;
- 戴尔和中国科学院自动化研究所合作共同建设基于深度学习的服务平台“诸葛• 深知”:“诸葛·深知”不仅提供通用的服务平台,而且还能针对不同行业用户的需求,提供定制化的服务,提供定制化的深度学习算法模型训练及相关技术咨询培训,以加速应用落地;
如今,戴尔以“在中国,为中国”的理念,为越来越多的中国用户服务,不仅仅是上述提到的科研机构和高校,伴随着HPC应用的扩展,特别是在互联网领域的大量应用,戴尔也在为越来越多向互联网转型的企业提供全新的深度学习、人工智能解决方案。
今日,越来越多创新科技企业
为中国超算再提速,深耕行业应用
从“超算大国”迈向“超算强国”!
来源:至顶网云计算频道
好文章,需要你的鼓励


OpenAI与微软签署初步协议修订合作条款
OpenAI和微软宣布签署一项非约束性谅解备忘录,修订双方合作关系。随着两家公司在AI市场竞争客户并寻求新的基础设施合作伙伴,其关系日趋复杂。该协议涉及OpenAI从非营利组织向营利实体的重组计划,需要微软这一最大投资者的批准。双方表示将积极制定最终合同条款,共同致力于为所有人提供最佳AI工具。

让AI推理像人一样思考,但又要快得多:中山大学团队的“智能剪刀“如何给O1模型瘦身
中山大学团队针对OpenAI O1等长思考推理模型存在的"长度不和谐"问题,提出了O1-Pruner优化方法。该方法通过长度-和谐奖励机制和强化学习训练,成功将模型推理长度缩短30-40%,同时保持甚至提升准确率,显著降低了推理时间和计算成本,为高效AI推理提供了新的解决方案。

国产R1人形机器人亮相,挑战特斯拉Optimus霸主地位
中国科技企业发布了名为R1的人形机器人,直接对标特斯拉的Optimus机器人产品。这款新型机器人代表了中国在人工智能和机器人技术领域的最新突破,展现出与国际巨头竞争的实力。R1机器人的推出标志着全球人形机器人市场竞争进一步加剧。

视觉语言模型在自动驾驶中的可靠性大考验:上海AI实验室深度揭秘AI司机的真实水平
上海AI实验室研究团队深入调查了12种先进视觉语言模型在自动驾驶场景中的真实表现,发现这些AI系统经常在缺乏真实视觉理解的情况下生成看似合理的驾驶解释。通过DriveBench测试平台的全面评估,研究揭示了现有评估方法的重大缺陷,并为开发更可靠的AI驾驶系统提供了重要指导。

