
GPU是怎么勾搭NVMe的?
很久很久以前,CPU和内存是分离的,内存控制器位于北桥。CPU每次取数据都要经过北桥中转,CPU嫌太慢,于是,把内存控制器直接集成到了自己内部,而北桥则只保留PCIE控制器。再后来,嫌PCIE控制器也离得太远了,就也把它收归麾下,北桥成了光杆司令,于是退出了历史舞台。现在的主板上只有CPU和I/O桥在一唱一和。
突然不知哪天,杀出来了个GPU,之前人们也未曾想过GPU除了渲染图像还能做更多事情,甚至被用来挖矿。GPU也要访问内存,但是现在访问内存要从CPU走一圈,GPU不干了,明明是我在计算,CPU只是控制,为啥我要不远万里从CPU那取数据。于是,GPU和NVMe盘开始勾搭上了。欲知详情,往下看。
R840/R940xa服务器简介
5月8日,DellEMC宣布了两款新服务器: PowerEdge R840和R940xa。这两款服务器都是4路CPU机型,将于2018年第二季度上市。
R840支持多达24个直连(直连到CPU,未经过PCIE Switch)NVMe驱动器和2个GPU卡或FPGA卡作为CPU加速器。在Monte Carlo Risk Analysis模拟中,R840相比R820快3.5倍。支持OpenManage RESTful API管理和用于DevOps集成的IDRAC9。显然,R940xa和R840面向的市场除了传统高端服务器市场外还可以定位到人工智能(AI)、机器学习和数据分析场景。

此外R840最大支持48个DIMM内存槽,以及最高12个NVDIMM槽位。支持RDIMM /LRDIMM,最大速率2666MT/s,最大容量6TB。
R840前背板有24个2.5槽位,或者8个3.5槽位,对应着不同的背板可选。具体支持的选项如下:最多8个3.5” SAS SATA (HDDs/SSDs) ,或者最多24个2.5” SAS/SATA (HDDs/SSDs),或者最多24个 NVMe PCIe SSDs,或者SAS/SATA盘与NVMe盘混插(NVMe盘数量最多12个)。这些不同的选项对应了不同的背板选择。前面板还支持额外2个2.5 SAS/SATA盘位。
NVMe与SAS/SATA混插的具体场景,冬瓜哥很早之前就写过一篇文章介绍。有兴趣可以阅读:【冬瓜哥画PPT】最完整的存储系统接口/协议/连接方式总结一文的后面部分。
R940xa为一款4U4路的机型。最大可支持4个双槽占位的GPU卡或者8个FPGA卡。硬盘槽位可达32个,其中4个可以用于SAS/SATA和NVMe混插。R940xa(“XA”代表“eXtreme Aggregation”),因为它的最大GPU:CPU为1:1。


GPU是怎么勾搭NVMe的
R840和R940xa这次无一例外的都支持大量NVMe槽位。GPU配NVMe,也算是好马配好鞍。由于GPU运算时可能需要吞吐大量数据,硬盘如果拖了后腿,那么就喂不饱GPU。但是,NVMe是连接到CPU上,而NVMe的数据也需要先到DDR RAM,然后才能被GPU访问。而DDR RRAM也是连接到CPU上。如下图所示▼
看到上面的图,是不是感到,任何数据都要进CPU转一圈,只因为DDR controller被集成到CPU内部了。这完全多此一举,为何不能让GPU直接从NVMe读数据呢?
其实是可以的,只要GPU内部跑一个NVMe驱动就可以了,并负责NVMe的枚举、初始化操作,这样就与CPU完全没什么关系了。但是这样做会让Mr.CPU感到很尴尬,没它啥事了。最好的办法是依然让Mr.CPU+OS来枚举初始化和配置NVMe,但是读写数据的时候可以让GPU与NVMe直接沟通。
NVMe盘是带有DMA Engine的,只要将DMA目标地址设置为GPU BAR内的某个空间即可让NVMe盘将数据DMA到GPU BAR内,或者从GPU BAR拿出来。而GPU并不会把它内部所有存储器都映射到BAR里,只可以做到现用现分。所以要求对应的GPU必须支持这种P2P bypass CPU方式。
▼
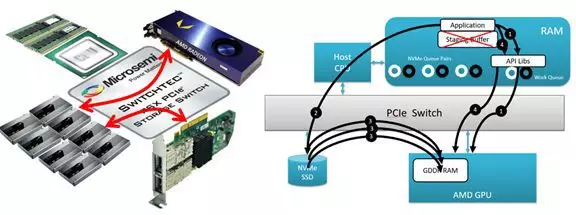
AMD GPU的DirectGMA技术便是这样一种技术。如上图所示:
? 第一步通过GPU提供的编程库向GPU申请一块显存,GPU传回指针。
? 第二步配置NVMe的DMA engine让其将数据DMA到对应指针处。
? 第三步DMA数据,这一步直接bypass CPU/RAM,直接通过PCIE通道实现NVMe与GPU的直接勾搭,延迟下降一大截。
? 第四步调用GPU编程库通知GPU开始计算。
实现上述的P2P传输过程需要一个部件的参与,那就是PCIE Switch。目前市场上主流产品为Microsemi公司提供的PCIE Switch产品。如下图所示,当采用了GPU到NVMe的P2P之后,其性能大幅提升。可节省host一端的投资,比如RAM使用量和性能可以下降,CPU规格可以下降,CPU与PCIE Switch的连接通道可以为x4甚至x2,节省PCIE通道的耗费量。
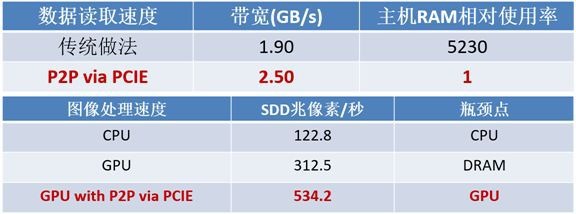
来源:DELL
好文章,需要你的鼓励



Queen‘s大学重磅研究:程序员的角色即将彻底改变,从码农到智能体指挥官
Queen's大学研究团队提出结构化智能体软件工程框架SASE,重新定义人机协作模式。该框架将程序员角色从代码编写者转变为AI团队指挥者,建立双向咨询机制和标准化文档系统,解决AI编程中的质量控制难题,为软件工程向智能化协作时代转型提供系统性解决方案。

苹果发布 iOS 26.0.1 系统更新,修复多项关键问题
苹果在iOS 26公开发布两周后推出首个修复更新iOS 26.0.1,建议所有用户安装。由于重大版本发布通常伴随漏洞,许多用户此前选择安装iOS 18.7。尽管iOS 26经过数月测试,但更大用户基数能发现更多问题。新版本与iPhone 17等新机型同期发布,测试范围此前受限。预计苹果将继续发布后续修复版本。

医疗AI的“显微镜革命“:西北工业大学团队发布首个超声影像专用智能助手EchoVLM
西北工业大学与中山大学合作开发了首个超声专用AI视觉语言模型EchoVLM,通过收集15家医院20万病例和147万超声图像,采用专家混合架构,实现了比通用AI模型准确率提升10分以上的突破。该系统能自动生成超声报告、进行诊断分析和回答专业问题,为医生提供智能辅助,推动医疗AI向专业化发展。
2018
06/01
18:57
分享
点赞

业界首款符合AEC-Q200标准额定电压高达1,000 VDC高压保险丝
数据中心的智算挑战,英特尔要如何应对?
下一代智能工厂怎么建?开放自动化给出“解题思路”
跟随西门子,在工博会感受沉浸式的工业AI体验
苹果发布 iOS 26.0.1 系统更新,修复多项关键问题
OpenAI将发布类似TikTok的社交应用,搭配Sora 2视频模型
微软推出Office智能体模式让用户"氛围办公"
AI助手现在能帮你创建高质量Word文档和Excel表格
高通新一代骁龙平台将推动智能体AI时代到来
SAPx阿里云,开启一条通往中国市场与全球化发展的全新路径
微软推出"氛围工作"模式,为Office套件加入AI智能体
OpenAI推出智能购物系统挑战谷歌亚马逊
