
MLPerf(TM) AI性能基准测试正式收官,戴尔科技荣获11项固定任务赛道冠军

AI基准测试MLPerf™公布了最新一期榜单MLPerf™ Training v1.1,至此2021年度MLPerf™ 4次测试正式收官。
戴尔科技夺得11项固定任务赛道冠军,在MLPerf™2021年度冠军榜中名列第三。戴尔易安信PowerEdge XE8545及PowerEdge R750xa,亦在最新一期测试中取得优秀成绩。
MLPerf™ AI性能基准测试
MLPerf由图灵奖得主大卫•帕特森(David Patterson)于2018年联合顶尖学术机构发起成立,历届参赛成员包括谷歌、英伟达、英特尔、微软、戴尔、腾讯等国际顶尖企业及研究机构,是权威性最大、影响力最广的国际AI性能基准测试,相当于全球AI领域的“奥运会”。

MLPerf™ AI性能基准测试包含Training(训练)和Inference(推理)两大领域,分为封闭任务赛道和开放任务赛道。
它基本涵盖了主流的机器学习服务器系统,并且从不同维度对系统性能给出了评价指标,在AI应用日益复杂多样的今天,为广大用户提供了AI计算方案设计及选型的权威参考。
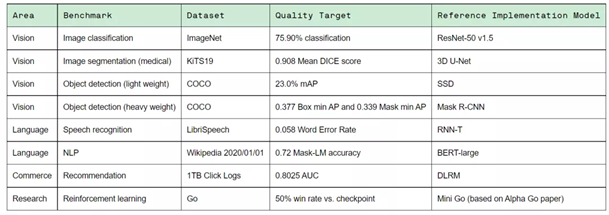
上周发布的MLPerf™ Training v1.1,涵盖图像分类(ResNet-50)、医疗图像(3D U-Net)、目标检测(SSD)、目标监测(Mask R-CNN)、语音识别(RNN-T)、自然语言处理(BERT-Large)、推荐系统(DLRM)、强化学习(Mini Go),共计8个子目。
01
单机系统测试
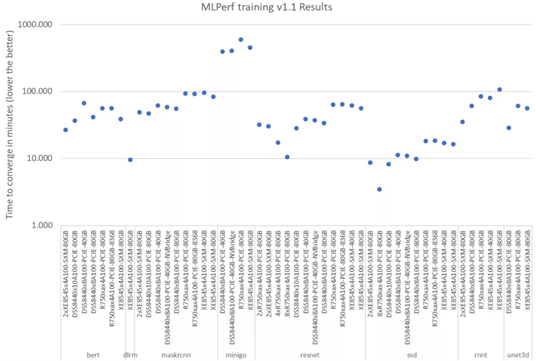
在MLPerf™ Training v1.1基准测试中,戴尔易安信共提交了51项测试结果,包括全部8个项目的性能数据。
GPU服务器硬件平台涵盖PowerEdge XE8545、R750xa和DSS8440三款GPU服务器,GPU选型包括A100 80GB/40GB、NVLink与PCI-E接口以及NVBridge互联的GPU加速卡等不同硬件组合。
通过不同服务器加GPU组合的结果数据对比,用户可以方便地进行比较,并获得不同的AI加速服务器选型基准性能数据参考。
其中,PowerEdge XE8545 + 4卡A100 80GB SXM4的产品组合,参加了8个项目的性能测试,表现相当亮眼:
●在所有参与MLPerf™ Training v1.1的四卡GPU加速服务器中,PowerEdge XE8545取得了目标检测(SSD)、目标检测(Mask R-CNN)、语音识别(RNN-T)、自然语言处理(BERT)、强化学习(Mini Go)五个项目的最佳成绩。
●在自然语言处理BERT-Large测试中,PowerEdge XE8545计算性能相较上一次MLPerf™ Training v1.0,训练时间缩短了18%。

戴尔易安信的测试数据、配置及Log,均可以在GitHub上找到:
https://sourl.cn/3FXXed
02
集群系统测试
除了GPU服务器单机测试外,戴尔易安信也是少有的提供基于GPU多机分布式训练测试结果的三家厂商之一。
集群系统测试出战的是PowerEdge R750xa,单台配置4块NVIDIA A100 80GB GPU,分别遵循以下模式进行MLPerf™ ResNet-50基准测试。
?单机(4卡)
?2台服务器(8卡)
?4台服务器(16卡)
?8台服务器(32卡)
测试结果如下:
▍两台R750xa训练性能可以达到单台R750xa的1.96倍,几乎是线性加速;
▍四台R750xa 16卡A100分布式训练,计算性能相当于单台的3.63倍,仍然保持良好的GPU加速效果;
▍使用16张A100 80GB的R750xa加速集群,17.336分钟即可完成ResNet-50模型训练;
▍使用32张A100 80GB的R750xa加速集群,10.586分钟就可以完成ResNet-50训练。
针对超大型模型,多机分布式训练势在必行。
今年早先时候,戴尔易安信在国内发布了《戴尔科技AI GPU分布式训练技术白皮书》,将戴尔易安信在构建AI GPU加速集群,进行AI GPU分布式训练全局优化的参考架构和最佳实践分享给更多的用户和朋友。

戴尔易安信AI加速服务器
台上一分钟,台下十年功,戴尔易安信GPU服务器在MLPerf™ Training v1.1基准测试中的不俗表现来源于其先进的技术配置。
PowerEdge XE8545
4U机架式空间内可以支持4张NVIDIA A100 80GB/40GB GPU加速卡,通过最新的NVLink加速技术实现Pear to Pear全互联。
PowerEdge XE8545服务器设计简单直接,CPU与GPU、GPU与GPU、CPU与网卡及NVME SSD存储,采用PCI-E 4.0或者NVLink实现直连,可最大程度降低通信及IO延迟。
使用XE8545单机4卡训练ResNet-50图像分类模型,计算性能为上一代4卡V100 NVLink GPU服务器的2.3倍。
PowerEdge R750xa
PowerEdge R750xa是首次参加MLPerf™ Training基准测试,同样取得了在四GPU加速服务器单机及集群测试领先的优异成绩。PowerEdge R750xa在2U空间支持4张双宽GPU的加速服务器,可耐受高达35度环境温度使用空气进行冷却。
它支持更丰富的GPU选型,包括A100/A40/A30/A10/A16/T4/A2等。PowerEdge R750xa还支持NVLink Bridge加速通信技术,针对A100、A40、A30 GPU,通过NVLink通道可以实现两个GPU之间的高速互联通讯。
R750xa可安装多达8个SAS/SATA固态硬盘或NVME SSD硬盘,提供NVME硬件RAID卡保护机制;与系统软RAID机制相比,硬件RAID卡在性能和可靠性上更有保证,可确保GPU服务器本地NVME SSD存储以最高性能稳定工作。
PowerEdge DSS8440
高密度GPU服务器,在4U机架式空间内最高可以支持10块如NVIDIA A100双宽GPU加速卡,或者16块单宽GPU。
同8卡GPU加速服务器相比,单机GPU计算密度提高25%,DSS8440同时提供对Graphcore IPU AI专用加速芯片的支持。

AI时代,应对指数级增长的数据,仅由CPU提供算力的传统服务器显得捉襟见肘,而擅长处理图形渲染、计算视觉、机器等密集型运算应用的GPU服务器,经验证足以扛起AI发展大旗。戴尔易安信AI加速服务器,支持苛刻的AI工作负载,助您轻松高效应对AI大潮。
来源:戴尔
好文章,需要你的鼓励


苹果48GB M5 Pro MacBook Pro创历史新低,直降300美元
B&H近期对多款M5 Pro MacBook Pro机型推出300美元优惠。14英寸M5 Pro版本(48GB内存+1TB固态硬盘)现售价2299美元,较原价2599美元节省300美元,且该配置在亚马逊无法购买,折扣机会更为难得。此外,16英寸M5 Pro版本(64GB内存+1TB固态硬盘)同样享有300美元折扣。B&H在多款高配MacBook机型上的定价已低于亚马逊,是近期可找到的最优价格。

AI助手越权了?南加州大学等机构揭示大模型代理的“权限失控“问题
FORTIS是专门测量AI代理"越权行为"的基准测试,研究发现十款顶尖模型普遍选择远超任务需要的高权限技能,端到端成功率最高仅14.3%。

Insta360 GO 3S复古套装:怀旧美学与4K影像的融合
Insta360推出GO 3S复古套装,将现代4K运动相机与胶片时代美学结合。套装核心仍是仅重39克的GO 3S,新增复古取景器、胶片风格滤镜、NFC定制外壳及可延长录制时长至76分钟的电池组。复古取景器模仿老式腰平相机设计,鼓励用户放慢节奏、专注构图。相机内置11种色彩预设及负片、正片等滤镜,同时保留FlowState防抖、4K拍摄及10米防水能力,面向热衷复古影像风格的年轻创作者。

荷兰Nebius团队:给AI“起草员“瘦身,大模型推理速度最高提升5倍的秘密
荷兰Nebius团队提出SlimSpec,通过低秩分解压缩草稿模型LM-Head的内部表示而非裁剪词汇,在保留完整词汇表的同时将LM-Head计算时间压缩至原来的五分之一,端到端推理速度超越现有方法最高达9%。
2021
12/10
14:52
分享
点赞

CarPlay 新增两款音频应用,让你的旅途更精彩
Insta360 GO 3S复古套装:怀旧美学与4K影像的融合
谷歌免费存储空间调整:未绑定手机号仅享5GB
美国三大运营商携手卫星技术,向信号盲区宣战
Flytrex无人机携手达美乐,可一次性送达两个大号披萨
欧洲最大3D打印公寓楼提前数月竣工
彼亚乔携手迪士尼推出Grogu主题自主跟随货运机器人
Okta将AI智能体安全管理扩展至Amazon Bedrock并向第三方身份提供商开放
苹果13英寸iPad Pro Magic键盘键盘亚马逊历史低价,直降25%
WhatsApp iOS版Liquid Glass界面设计正式向更多用户推送
OpenAI为ChatGPT Pro推出个人财务管理新功能
赛格威全新Xaber 300电动越野摩托车正式开售,最高时速达96公里
