
Azure AI的又一里程碑!Neural TTS新模型呈现真人般情感饱满的AI语音
在人与人之间的对话中,即使是同样的字句,也会因为所处情景和情感的不同而表现出丰富的抑扬顿挫,而这种动态性恰恰是各种AI合成语音的“软肋”。相比于人类讲话时丰富多变的语气,AI语音的“心平气和”往往给人带来明显的违和感。
如何让AI语音有效模仿人类对话的丰富动态与情感,已成为全球研究者的共同挑战。就在不久前,微软Azure Neural TTS(神经网络文本转语音)推出的新一代模型“Uni-TTS v4”在这一领域取得了里程碑式的重大突破。在“2021国际语音合成大赛(Blizzard Challenge 2021)”的测试中,Uni-TTS v4的语音表现与通用数据集上的自然语音相比几乎没有明显差别,展现出足以“叫板”真人对话的实力。
Uni-TTSv4的研究出发点是XYZ-代码,它是三种认知属性的联合表示:单语文本(X),音频或视觉感官信号(Y),以及多语言(Z)。关于这些努力的更多信息,请阅读XYZ-代码的博文。
“耳听”为实,让我们从以下几段TTS和真人对话的对比中,感受新模型带来的逼真语音表现。
En-US(Jenny):
The visualizations of the vocal quality continue in a quartet and octet.
真人录音: https://www.microsoft.com/en-us/research/uploads/prod/2021/12/Jenny_NonTTS-recording.wav
Uni-TTS v4: https://www.microsoft.com/en-us/research/uploads/prod/2021/12/Jenny_TTS_new.wav
En-US(Sara):
Like other visitors, he is a believer.
真人录音: https://www.microsoft.com/en-us/research/uploads/prod/2021/12/Sara-NonTTS-recording.wav
Uni-TTS v4: https://www.microsoft.com/en-us/research/uploads/prod/2021/12/Sara-TTS-new.wav
Zh-CN(Xiaoxiao):
另外,也要规避当前的地缘局势风险,等待合适的时机介入。
真人录音: https://www.microsoft.com/en-us/research/uploads/prod/2021/12/Xiaoxiao-NonTTS-RECORDING.wav
Uni-TTS v4: https://www.microsoft.com/en-us/research/uploads/prod/2021/12/Xiaoxiao-TTS-NEW-Wave.wav
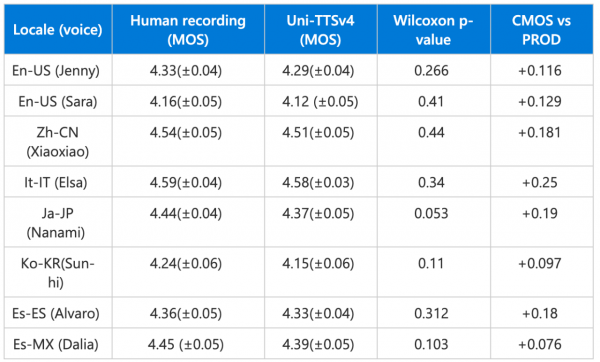
图注:上图为Uni-TTS v4在“2021国际语音合成大赛(Blizzard Challenge 2021)”上的测试结果。这项TTS领域的全球盛事汇集了全球顶级专家,每次都会邀请数百名参会者对多个TTS系统进行大规模MOS测试,称得上是全球TTS“试金石”。相关详细信息可以参看微软为此次活动发表的论文《DelightfulTTS: The Microsoft Speech Synthesis System for Blizzard Challenge 2021》。
如果体验完以上示例后还觉得意犹未尽,欢迎在Azure TTS在线服务中使用自创文本来创建新的demo。目前Uni-TTS v4可支持TTS语言库中7个语种的8个语音,研发团队还将持续使用最新模型优化Neural TTS已支持的其它语言以及自定义神经语音,以便能让用户通过Azure TTS API、 Microsoft Office和Edge browser直接获得更出色的新一代TTS语音。
Uni-TTS v4之所以能成为Azure AI的又一里程碑,在于其出色拟真语音表现的背后,对TTS语音基础建模的大幅革新。
如同开篇所说,TTS语音与真人的差距在于难以模仿人类对话的丰富动态。人类在不同的情绪或场景下,对同一个词的发音方法可能完全不同,而且其变化规律在不同语种中也千差万别。
TTS语音的表现依赖于以各种声学参数进行建模,但这些参数很难有效地对人类语音声学频谱上的所有粗粒度和细粒度细节进行建模。另一方面,TTS是一种典型的一对多映射,往往需要使用多种语音风格(如音调、语速、讲话人、韵律、风格等等)来输出同一个文本内容。总之,能否为这些“变量”进行有针对性的建模,是提升合成语音表现力和真实度的重要因素。
为了让TTS在以上两方面获得提升,Uni-TTS v4在声学建模中引入了两项重要更新。通常,transformer模型用来学习全局交互,而卷积神经网络则有效地发现局部相关性。于是研究团队首先采用了一个带有transformer和卷积块的新架构,以更好地模拟声学模型中的局部和全局依赖关系;其次,从显性视角(身份ID、语种ID、音调、语速)和隐性视角(话语级和音素级韵律)系统地对变量信息进行建模。这些视角分别使用监督学习和无监督学习,确保端到端的音频具有足够自然的表现力。
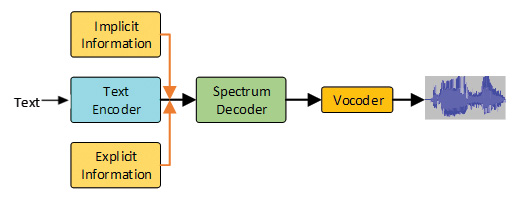
图注:Uni-TTS v4 的声学模型和声码器示意图。首先使用文本编码器对文本进行编码,然后将隐性和显性信息添加到文本编码器的隐藏嵌入(hidden embeddings)中,再使用频谱解码器预测梅尔声谱图。最后,通过声码器将梅尔声谱图转换为音频样本。
作为微软Azure认知服务中的强大语音合成功能,Neural TTS可用于帮助开发者将文本转换为真人一般的逼真自然语音,常被用于语音助手场景、文字朗读功能,及作为辅助性工具等等,同时也被整合到微软的Edge Read Aloud、Immersive Reader和Word Read Aloud等旗舰产品中,还被AT&T、Duolingo、Progressive等众多客户采用。Neural TTS已拥有330多个音色,支持来自不同国家和地区的近130种语言或方言。用户和企业可以通过搜索"Azure TTS"进入产品网站,测试体验Neural TTS的丰富预设语音,抑或录制并上传自己的样本,来创建独有的自定义语音。
来源:业界供稿
好文章,需要你的鼓励


豪声电子泰国电声工厂初步投产:2500万泰铢项目进入产能爬坡
今天讲的出海案例是生产微型扬声器、受话器和音响产品的豪声电子,其计划投资2500万泰铢的泰国音响类电声工厂已经进入初步投产阶段。

马萨诸塞大学的研究者们证明了:搜索引擎的“比较策略“在数学上优于传统方法
马萨诸塞大学从数学角度证明,MaxSim评分策略在理论能力上超越传统单向量内积方法,并提出Signed MaxSim扩展,显著改善否定查询性能。


新加坡国立大学与英伟达研究院联手打破视频生成的“非此即彼“困局:一个模型,两种能力,任意切换
新加坡国立大学与英伟达联合提出Flex-Forcing框架,通过时间帧和去噪步骤两个维度的灵活分块,将双向扩散和自回归视频生成统一到单一模型中,实现质量与效率的自由权衡。
2022
01/27
15:17
分享
点赞

“驯服”千亿模型,鏖战“黑猴打瓦”,龙虾“一键接管” ,锐龙AI Max+ 395开启全能桌面AI主机“王炸”时刻
豪声电子泰国电声工厂初步投产:2500万泰铢项目进入产能爬坡
地瓜机器人将560TOPS端侧算力,加载到了20+头部团队机器人中
WAIC 2026主论坛(下午场)重磅揭晓!
AI评测初创公司Braintrust遭入侵,敦促所有客户轮换API密钥
牙科诊所软件漏洞修复:患者医疗记录曾遭泄露
关键基础设施巨头Itron确认遭遇网络攻击
Vercel数据泄露范围扩大,黑客早于已知时间节点已入侵
苹果与博通签署300亿美元协议,共同生产美国本土无线芯片
摩托罗拉领投BRINC 1.25亿美元,推动紧急救援无人机大规模扩张
AI赋能芯片设计:前景广阔,疑问犹存
Arm今夏将推出自研芯片,Meta成首批客户
Azure AI Week 直播课表公布,12月10 -12日线上见
微软、谷歌云和AWS第三季度云业绩对决
微软Azure上线基于Arm架构的Cobalt 100 CPU虚拟机
微软精心打造Rust虚拟机管理程序,为Azure工作负载提供动力
微软公布详尽计划,将分阶段对Azure用户强制做出MFA要求
市场分析:AWS、微软和谷歌云2024年第二季度云业绩对决
微软公布Azure Logic应用混合部署预览,“睽违已久”的C#内联操作终于落地
Oracle Autonomous Database服务登陆Azure
西门子与微软合作实现数字孪生定义语言标准化
Dell APEX File Storage for Microsoft Azure助力企业实现全面AI
