
刷新中文命名实体识别SOTA,华为云论文入选国际顶会NAACL 2022
4月7日,自然语言处理领域国际顶级学术会议NAACL 2022(The North American Chapter of the Association for Computational Linguistics)公布论文入选名单,由华为云语音语义创新Lab多名研究者撰写的信息抽取论文《Delving Deep into Regularity: A Simple but Effective Method for Chinese Named Entity Recognition》被NAACL 2022 Findings接收,这代表着中文命名实体识别的最优结果 (SOTA) 被进一步刷新,更准确有效的实体识别将推动下游自然语言处理任务的进一步发展。
NAACL由国际计算语言学学会(ACL)主办,与ACL、EMNLP并称NLP领域的三大顶会,是人工智能的重要研究阵地。NAACL的录用十分严格,根据往年评选结果,只有不到30%的论文被接收。
作为自然语言处理中最经典、最基础的任务,命名实体识别一直受到广泛的关注与研究。近年来,中文命名实体识别任务上取得了明显进展,很多新的方法和框架被陆续提出,但往往忽略了实体词的内部组成。
对于中文命名实体而言,很多类别的实体都具有很强的命名规律性。比如说,以“公司”或者“银行”结尾的实体词,通常属于组织机构这一实体类别。因此,在《Delving Deep into Regularity: A Simple but Effective Method for Chinese Named Entity Recognition》中,华为云语音语义创新Lab的研究者提出用简单有效、规律性引导的识别网络来探究中文实体词中的规律性。
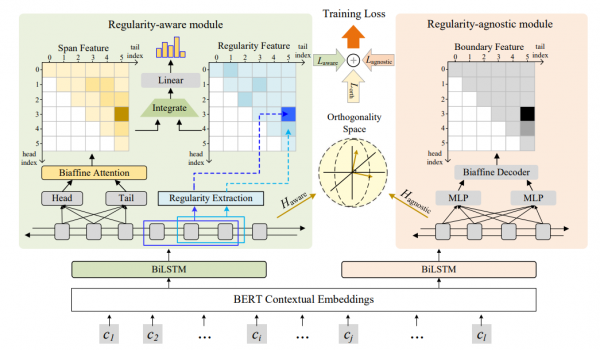
图1 规律性引导的识别网络
如图1,华为云研究者首先利用注意力机制显著地提取每个文本段的规律性,进而将这种表征文本内部的规律性的特征和通过Biaffine Attention提取的文本段特征结合起来,进行后续的实体识别。为了避免由于过度关注实体内部规律性导致的实体边界识别偏差,研究者们另外设计了一个与规则无关的模块来帮助模型更准确地识别实体的边界。
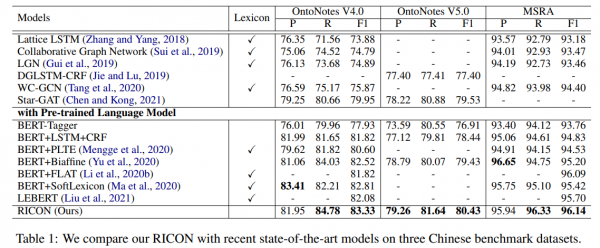
图2 中文数据集上的实验结果
华为云研究者提出的规律性引导的识别网络,如图2,在MSRA, Ontonotes4.0, 和Ontonotes5.0三个大规模中文实体识别数据集上都取得了SOTA的结果。同时,本文提出的方法不依赖于外部词典信息,并且F1值超过了目前所有使用词典信息的方法的结果。这充分说明通过研究实体词的内部规律性,研究者们提出了一个非常有效的网络结构。
不止在信息抽取方面,华为云语音语义创新Lab秉承开放创新、勇于探索、持续突破关键技术的精神,面向行业客户提供领先的语音语义AI能力,结合大量行业知识,推出知识计算等行业解决方案,打造业界一流的知识计算竞争力。截至目前,已在政务、金融、石油等多个行业进行了落地和实践,帮助客户实现AI落地与智能升级。
来源:业界供稿
好文章,需要你的鼓励


英特尔推出新芯片设计,聚焦能效与成本优化
英特尔推出旗舰Xeon 6+ CPU、Crescent Island GPU和新款以太网控制器,强调通过功耗优化和成本控制帮助客户平衡系统性能。新GPU采用LPDDR5X内存降低成本,Xeon 6+基于18A工艺并新增应用级能耗监测功能。分析师认为这有助于服务器整合和降低运营成本,但英特尔仍需在AI战略整合和CPU市场份额方面应对挑战。

俄亥俄州立大学打造出“全能深度研究助手“——只用8000道合成题,就让AI研究能力追平顶级商业系统
俄亥俄州立大学推出开源深度研究智能体Quest,仅用8000道全合成训练题,在8项主流基准上超越同类开源模型并局部超过OpenAI DeepResearch等商业系统,完整方案全部开源。


上交大与腾讯联合研发:当AI助手不再只是“等你开口“,它学会了在空闲时提前帮你准备好答案
上交大与腾讯联合研发的ProAct框架,让AI助手在对话空闲期主动预判用户下一步需求,提前备料,使完成任务所需对话轮次减少14.8%,用户提问次数减少11.7%,错误率下降28.1%。
2022
04/13
17:32
分享
点赞

英特尔推出新芯片设计,聚焦能效与成本优化
英特尔至强6+,为数据中心带来了什么?
Fortinet Accelerate 2026 亚太区巡展上海站,AI 双轮驱动重构网络安全新范式
泰国警察穿亮片裙装抓毒贩照片被证实为AI伪造
Meta正在研发AI智能挂坠,计划年内启动测试
GitHub Copilot改用Token计费模式,开发者叫苦不迭
iOS 27视觉智能新期待:为"提醒事项"赋能
AI能为澳大利亚养老行业带来更多人情味吗?
东芯股份赴香港筹 H 股,存储芯片公司的海外前台先行
EcoFlow限时48小时促销活动:12.2千瓦时储能电站套装优惠
Beats新款头戴耳机曝光:全新设计与粉色配色亮相
NextThere:一款为公共交通出行提供深度数据洞察的独立应用
