
Serverless + Data,让后端告别搬砖!
上古时期,软件系统都比较简单。


随着时代的发展,系统越来越复杂。
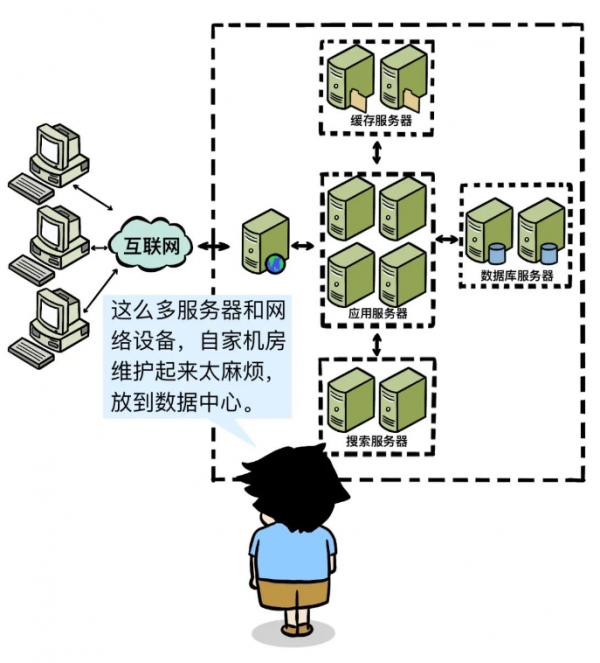
移动互联网时代来临,流量越来越大,尤其是搞促销活动的时候。
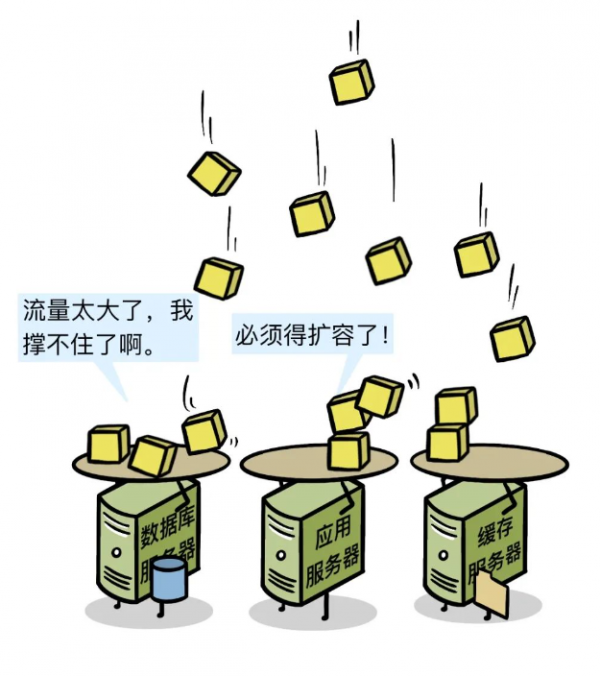

促销活动过后,领导到机房视察。



很快, 云计算时代来临了!


又到一年大促活动时。
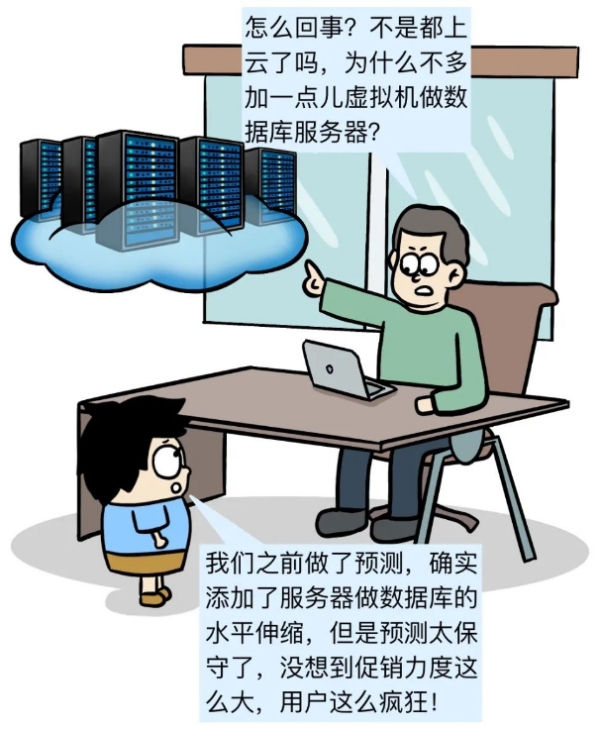
领导发现系统越来越慢,数据库已经开始报警了!



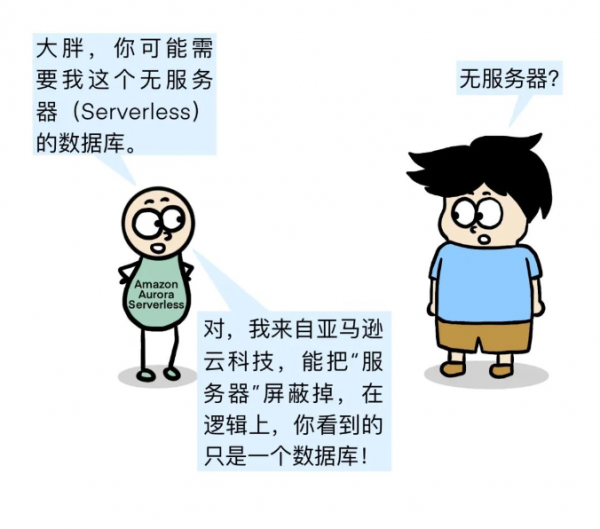
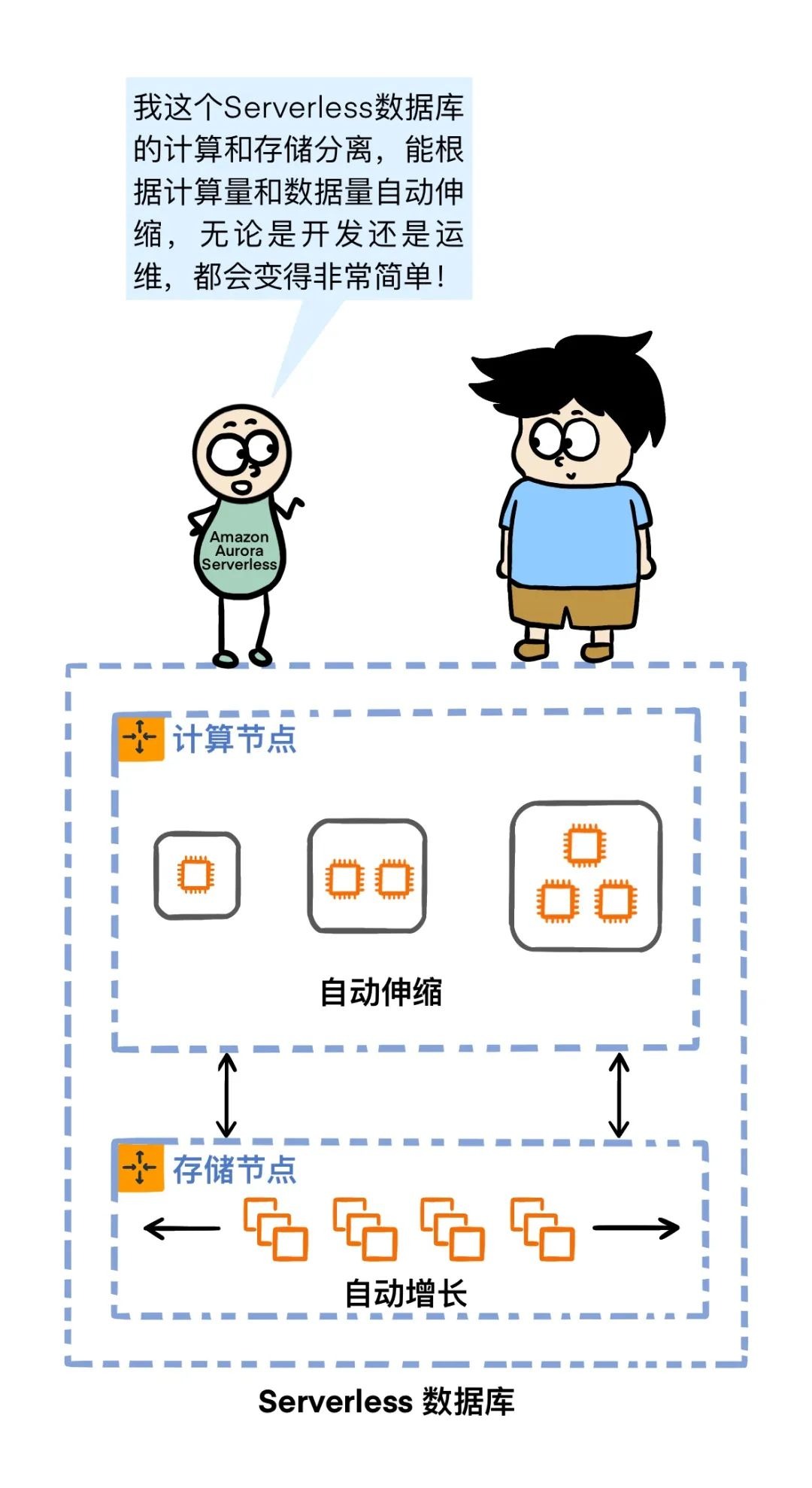
(架构参考自Amazon Aurora Serverless v2)

数据库的计算和存储能自动伸缩,流处理是不是也可以?

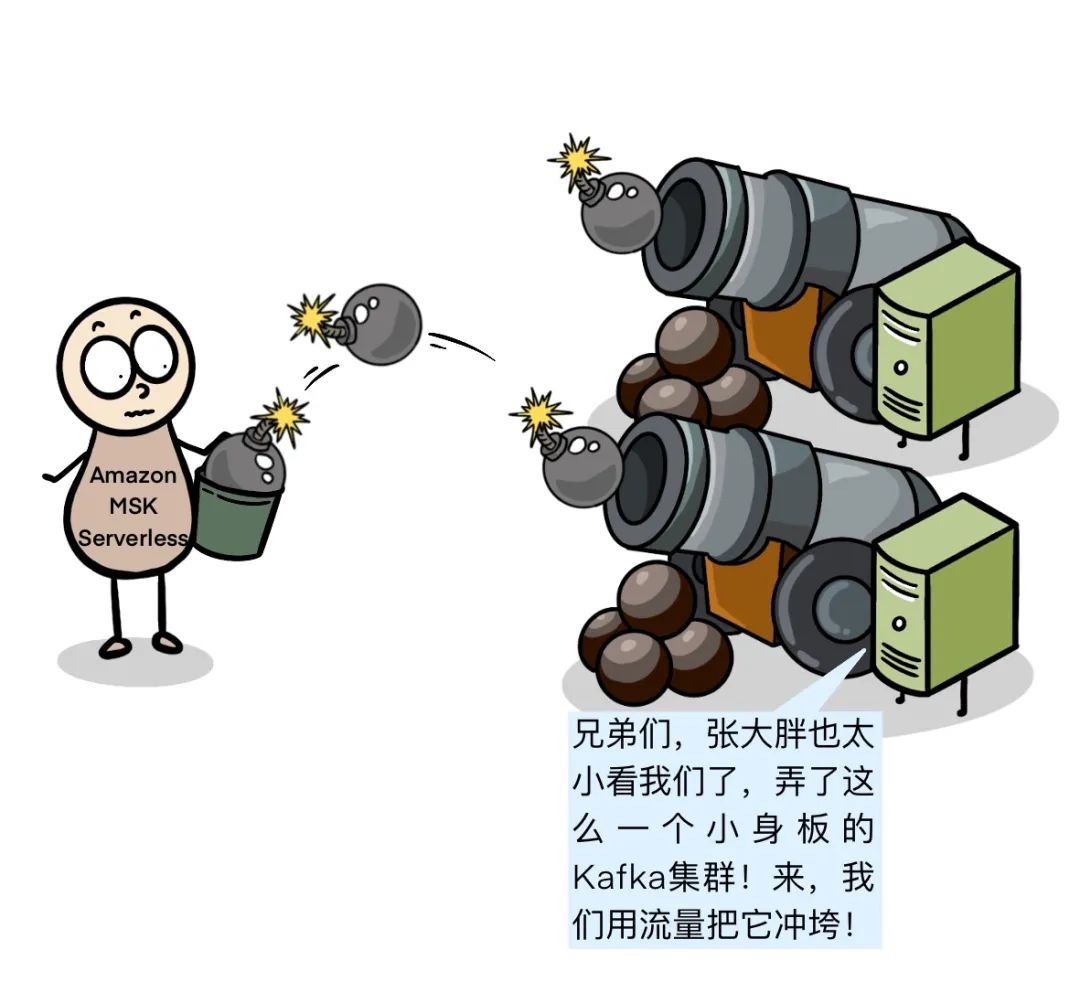
可是,一秒不到,Kafka集群自动扩容。


在大数据领域,无服务器化(Serverless)也可以大显身手。


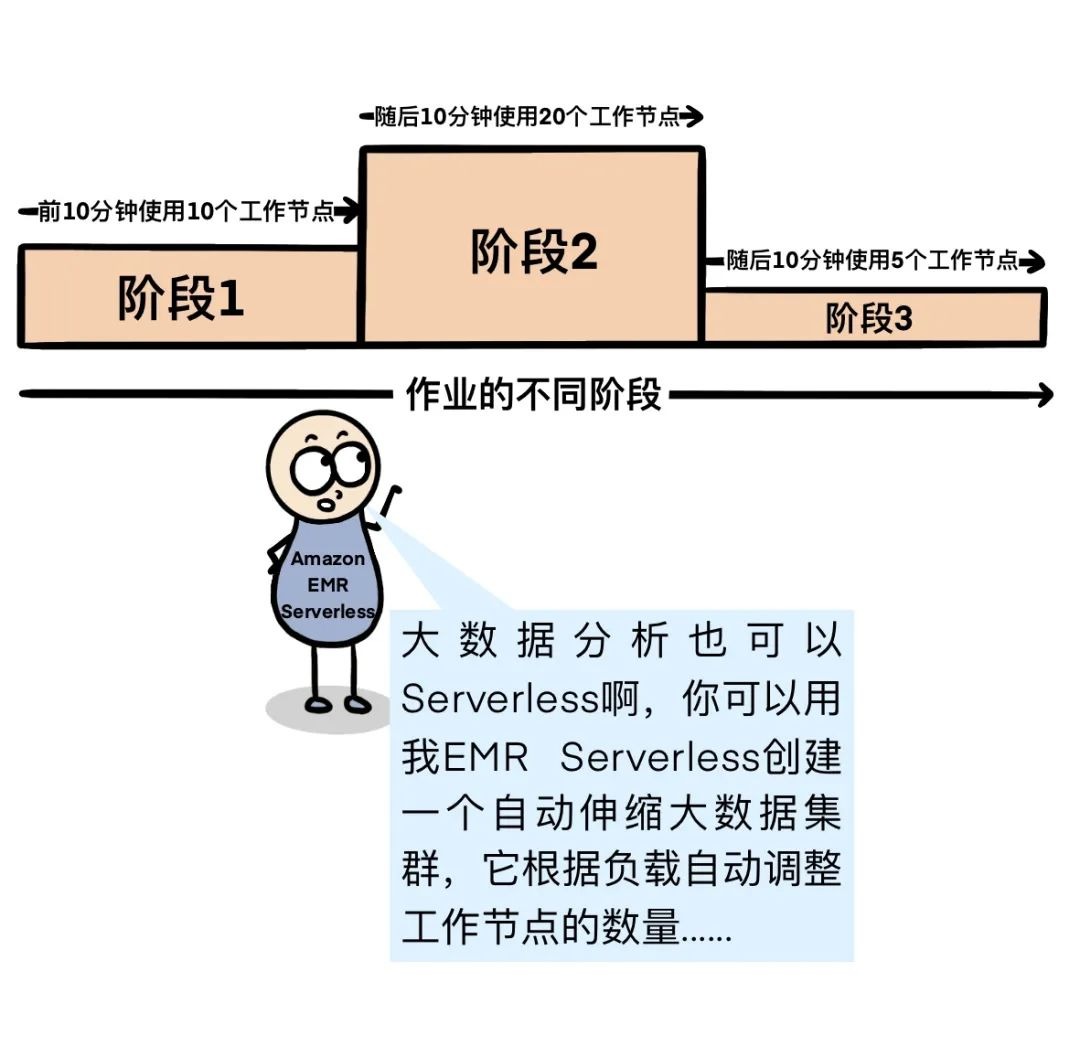
三天以后。

机器学习模型首先要经过历史数据的“训练”。

训练好的模型才能部署到生产环境,正式开始“推理”。



随着云计算的发展,Serverless的出现是个必然,因为它能极大地降低开发和运维的工作量。
Serverless从最早的单纯的函数计算,已经深入到了数据领域,无论是数据库、流处理、大数据分析、搜索、人工智能...... Serverless都可以大放异彩。

欢迎大家使用亚马逊Serverless服务,开启云原生数据之旅!
10月13-14日亚马逊云科技中国峰会分论坛上,将首次全面解析Severless云原生数据库,首次揭秘智能湖仓2.0,讲述如何打破数据孤岛,跨数据库、数据湖和机器学习,同时探讨无服务器数据库与数据分析的魅力,释放数据价值,助力企业更好做出决策。一起来一探究竟!
识别下方二维码或点击此处即可报名!

好文章,需要你的鼓励


8090 Solutions完成1.35亿美元融资,加速AI软件开发自动化布局
AI软件开发自动化初创公司8090 Solutions宣布完成1.35亿美元A轮融资,由Salesforce Ventures领投。8090由知名风险投资人Chamath Palihapitiya于2024年创立,其核心产品"Software Factory"是一款AI平台,通过自然语言文档帮助企业加速应用开发,支持现有程序现代化改造及全新应用构建。此次融资将用于扩充团队规模和基础设施建设。

港科大联手快手,让AI画图“减减肥“:一个让图像生成更真实的小技巧
港科大与快手联合提出NormGuard,针对流匹配模型强化学习训练中速度范数膨胀问题,通过训练时单向惩罚约束,在保留奖励的同时改善图像真实感。

Rocket Lab宣布以80亿美元收购卫星运营商铱星公司
火箭实验室(Rocket Lab)宣布计划以现金加股票方式,斥资80亿美元收购主要卫星运营商铱星通信(Iridium Communications),交易预计于2027年中完成。铱星目前运营着由66颗活跃低轨卫星组成的星座网络,拥有约255万活跃用户,2024年营收达8.717亿美元。收购完成后,Rocket Lab计划借助其新型重型运载火箭Neutron及Lightning卫星平台,扩大铱星星座规模,开拓未被覆盖的市场并降低发射成本。

谷歌研究院打造“论文助手工具“,AI审稿时代正在悄然开启
谷歌研究院开发的论文助手工具PAT,利用分阶段深度推理流水线自动审查学术论文,在真实错误检测任务上达到89.7%召回率,并已在STOC和ICML两大顶会完成超4700篇论文的真实部署。
2022
09/28
18:20
分享
点赞

AI重复申请问题推动电网转向"承诺优先"规划
美国消费品安全委员会拟出台电动自行车电池安全新规
江波龙:建设完成mSSD月产能百万交付能力!mSSD高速存储介质赋能端侧AI规模应用
从IO500双榜第一,看国产存储的系统级突破
8090 Solutions完成1.35亿美元融资,加速AI软件开发自动化布局
Rocket Lab宣布以80亿美元收购卫星运营商铱星公司
Tidal宣布将为AI生成音乐添加标签并移除欺诈内容
Claude Tag:将职场AI从个人助手升级为团队协作伙伴
数百万颗超新星爆炸或将揭开暗能量的秘密
Base44发布自研大语言模型,氛围编程平台寻求核心竞争壁垒
遗留系统与数据鸿沟制约亚洲财资中心发展
机器人手部公司与特斯拉达成商业秘密诉讼和解,完成1100万美元融资
