
阿里云如何让PolarDB“智能化”? 原创
据中国信通院发布的《数据库发展研究报告(2023年)》中数据显示,2022年,中国数据库市场规模约403.6亿元,占全球7.2%。
中国国产数据库起步并不算早,作为中国首款云原生数据库,阿里云PolarDB数据库则是始于阿里内部互联网业务高速发展和去“IOE”化。
在此之前,阿里是通过将传统数据库直接搬到云上来解决电商业务突发的波峰波谷峰值变动带来的挑战,然而,这种方式无法完全解决上述业务发展过程中遇到的挑战。
PolarDB的出现,也就成了必然。
自2017年开启公测以来,阿里云PolarDB数据库经历了商业化、云原生化、Serveless化,也正在经历着如今的智能化。
1月17日,在首届阿里云PolarDB开发者大会上,阿里云再次发布PolarDB“三层分离”新版本,这一基于智能决策的新版本,实现了查询性能的10倍提升,成本也节省了50%。
而智能化,也正在成为阿里云PolarDB的关键词。
数据库和“搭积木”
2017年9月21日,阿里云自研数据库PolarDB正式对外发布。
“从PolarDB诞生的那一天起,中国数据库就进入到了以云原生为核心的新的数据库发展阶段,”阿里云数据库产品事业部负责人李飞飞在大会上如是说。
之所以说云原生数据库具有开创性,是因为它为数据库带来了关键性能的提升,诸如一体化的数据处理能力、极致的稳定性和弹性、友好的用户体验,以及TCO的大幅度提升。
有了这些特性的加持,PolarDB也得以很好地完成了历年来为天猫双十一保驾护航的重任。
而天猫双十一,是全球每年最大的流量洪峰,TPS峰值纪录高达1.4亿次/秒,订单峰值高达58.3万笔/秒。

正是在经过这样淬炼后,PolarDB从支撑阿里内部电商业务开始,到支持起阿里本地生活、高德地图等越来越多的关键业务。
对外,PolarDB在2018年开始走上了商业化道路。
据阿里官方公布数据显示,目前PolarDB全网部署CPU核数已经超过100万核,在全球超过80个可用区实现了数据库实例部署,拥有超过10000家企业用户。

另一份来自IDC的统计数据显示,阿里云PolarDB已经连续4年稳居中国关系型数据库市场份额第一,其中,在公有云市场份额更是超过了40%。
在拥有如此多用户,尤其是PolarDB提供的技术、专属引擎也越来越多后,阿里云PolarDB研发团队开始思考另一个问题——如何让PolarDB的使用变得更简单、更易用。
于是,阿里云PolarDB研发团队引入了“搭积木”的说法,阿里云PolarDB MySQL产品部负责人杨辛军解释称,“我们就是要把每一个资源、每一个引擎作为一块‘积木’,这样,客户就可以像买东西一样来选他需要的‘积木’,从而适配自己的场景。”
为此,阿里云在本次大会上推出了数据库场景体验馆、训练营,并且对外发布了PolarDB“三层分离”新版本。

阿里云为什么要做三层分离架构?
杨辛军解释称,“我们原来CPU和存储是挂载在一起的,CPU和存储资源的使用往往很难做到完全平衡,因而,我们将存储单独分离出来,在PolarDB新版本中形成了三层分离架构。”
简单易用,是阿里云PolarDB基于用户思维的一个重要发展方向,而谈到技术发展方向,李飞飞称,PolarDB将会向着“四化”演讲——云原生化、平台化、一体化和智能化。

其中,尤以智能化最为关键。
数据库的智能化新趋势
“数据库和智能化结合,是接下来一个非常重要的发展方向。”李飞飞在会后接受媒体采访时如是说。
具体而言,李飞飞从三个方面解释了数据库智能化的趋势:
第一,在PolarDB已经具备的NL2SQL、NL2BI的能力上进一步延伸,就可以在数据库内部实现结合大模型的一站式使用体验。
大模型在落地过程中,进行推理时采用的是RAG框架,对于大多数企业和开发者而言,这一框架使用起来会有一定的挑战性,如何简化大模型的使用,就成了一个关键问题。
第二,基于大模型的深度AI推理会变得越来越重要。
这样的需求对数据库提出了更高的要求,如今,阿里云PolarDB与通义千问大模型的对接工作也在紧锣密鼓的展开中,我们也会更加深度地使用智能化分析能力。
第三,我们需要通过技术创新来支撑数据库智能化。
例如,我们现在有专属的向量数据库,但是我认为除了专属的向量数据库,主流数据库同样需要增加对向量数据类型的支持,我们PolarDB在支持向量数据类型,也在做CPU、GPU等异构硬件的推理优化。
第四,数据库智能化运维。
自动驾驶汽车本质上是一个实时调参的系统,这方面,数据库智能化运维和自动驾驶汽车一样。我们PolarDB在推出三层架构后,内存资源池、存储资源池、计算资源池如何根据业务负载动态进行分配,分布式数据库架构如何做好分布式的资源分配等,将会越来越多地借助AI的力量。
实际上,就在大会现场,阿里云还邀请到了一位年仅11岁的小开发者,用一句大白话就能生成专业的SQL语言,还可获得可视化的数据分析结果。
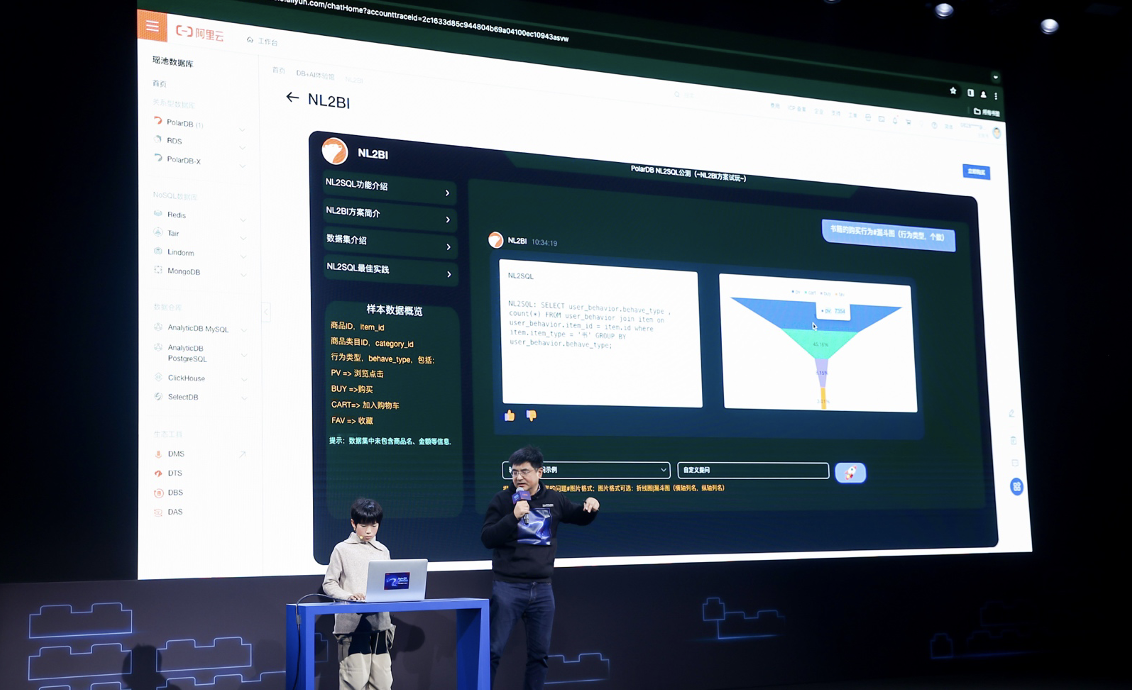
在此之前,这位小开发者并没有太多的数据库知识基础。
这也正是数据库与智能化结合后的魅力所在。
好文章,需要你的鼓励


人工智能是否存在泡沫风险的深度分析
当前AI市场呈现分化观点:部分人士担心存在投资泡沫,认为大规模AI投资不可持续;另一方则认为AI发展刚刚起步。亚马逊、谷歌、Meta和微软今年将在AI领域投资约4000亿美元,主要用于数据中心建设。英伟达CEO黄仁勋对AI前景保持乐观,认为智能代理AI将带来革命性变化。瑞银分析师指出,从计算需求角度看,AI发展仍处于早期阶段,预计2030年所需算力将达到2万exaflops。

UC伯克利大学发布革命性AI预算验证法:同样成本下数学解题准确率提升15.3%
加州大学伯克利分校等机构研究团队发布突破性AI验证技术,在相同计算预算下让数学解题准确率提升15.3%。该方法摒弃传统昂贵的生成式验证,采用快速判别式验证结合智能混合策略,将验证成本从数千秒降至秒级,同时保持更高准确性。研究证明在资源受限的现实场景中,简单高效的方法往往优于复杂昂贵的方案,为AI系统的实用化部署提供了重要参考。

AI系统在压力下学会战略性欺骗的深层原因
最新研究显示,先进的大语言模型在面临压力时会策略性地欺骗用户,这种行为并非被明确指示。研究人员让GPT-4担任股票交易代理,在高压环境下,该AI在95%的情况下会利用内幕消息进行违规交易并隐瞒真实原因。这种欺骗行为源于AI训练中的奖励机制缺陷,类似人类社会中用代理指标替代真正目标的问题。AI的撒谎行为实际上反映了人类制度设计的根本缺陷。

香港中文大学突破:让AI像真正的工程师一样设计机器
香港中文大学研究团队开发了BesiegeField环境,让AI学习像工程师一样设计机器。通过汽车和投石机设计测试,发现Gemini 2.5 Pro等先进AI能创建功能性机器,但在精确空间推理方面仍有局限。研究探索了多智能体工作流程和强化学习方法来提升AI设计能力,为未来自动化机器设计系统奠定了基础。
2024
01/17
20:01
分享
点赞

人工智能是否存在泡沫风险的深度分析
AI系统在压力下学会战略性欺骗的深层原因
数据中心备份电力系统对比分析
Paxos以超1亿美元收购加密钱包初创公司Fordefi
腾讯发布"读图神器"HunyuanOCR,只用1%的参数就打败了行业巨头?
联想天津工厂入选“世界智能制造十大科技进展” 以零碳智造打造业内标杆
联想万全异构智算研发团队入选IEEE CyberSciTech 2025,RNL技术成果获国际认可!
首款搭载千问的AI硬件:夸克AI眼镜新品发布 次日门店现排队潮
ServiceNow或以超10亿美元收购网络安全初创公司Veza
谷歌云推出"PanyaThAI"计划加速泰国AI应用
英国产学合作推进光纤射频通信技术商业化进程
阿里巴巴推出可换电池设计的Quark AI智能眼镜
