
华为云立体化运维为云原生应用赋能
作为云原生技术和实践的持续引领者,华为云一直致力于云原生产业的推动与发展。华为云提出,云原生2.0是企业智能升级新阶段,企业云化从“ON Cloud”走向“IN Cloud”,成为“新云原生企业”,新生能力与既有能力立而不破、有机协同,实现资源高效、应用敏捷、业务智能、安全可信。
华为云还发布云原生2.0全景图,其中,在应用敏捷层,华为云将云原生的全栈能力赋能客户,帮助客户应用敏捷、业务智能,安全可信,面向未来持续演进。其中,高效运维则是重要保障。
随着云原生2.0时代的来临,越来越多的企业及个人选择使用云原生技术来构建业务,云原生技术给业务构建、交付带了便利的同时,对运维也提出了更高的要求。
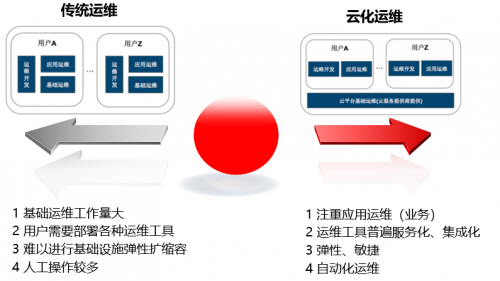
传统运维到云原生2.0场景运维有诸多区别,传统运维在基础资源方面工作量较大,需要自行构建运维系统,同时又难以进行基础设施维度的弹性扩容。而在云原生2.0场景下,基础资源运维大多由云厂商提供,所以用户可以有更多的精力来关注业务本身的运维,与此同时云厂商会提供更加通用、普适的运维产品,降低用户的运维工具构建成本。相比与传统运维,云原生2.0场景下的运维更加的弹性、敏捷,可以针对虚机资源、应用进行弹性扩缩容,以此来应对业务的高峰与低谷。
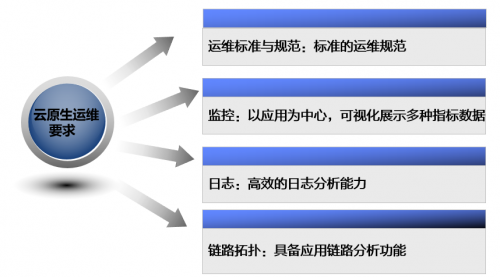
在云原生2.0场景下运维要求又有哪些?
首先,需要有一套高效的运维流程,依托标准的运维规范来完成日常的各种运维动作;其次运维工具也是必不可少的,需要有一套以应用为中心,并且能够具备可视化展示各种维度监控指标的监控平台;日志功能也是运维过程中必不可少的工具,通过日志收集、存储、分析等过程,展示各种日志文件分析后的数据,作为日常运维的重要依据;最后,链路拓扑也是自动化运维的重要功能点,由于应用下属的实例个数众多,需要可视化展示每个微服务实例之间的调用关系,出现问题时,下钻到微服务内部进行方法级别的故障诊断。
华为云立体运维解决方案是为云上客户量身定制的一个解决方案,包含AOM(应用运维管理服务)、APM(应用性能管理服务)、LTS(日志服务)。覆盖IaaS层的基础设施状态,Paas层的中间件及数据库状态,应用层的各类应用状态及指标这三层,形成立体化运维分析能力。华为云立体化运维解决方案遵循DevOps标准,可以敏捷高效的获取云上应用的各类异常,并辅助运维人员快速定位。同时立体化运维解决方案以应用为中心,展示应用指标、拓扑、状态信息,提供应用视角的监控运维模式,满足日常巡检、故障排查等多种运维场景。
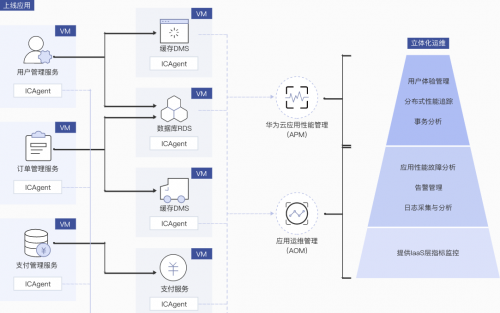
华为云立体运维解决方案具有以下特点:
1统一运维监控管理:资源、应用、业务一站式监控与分析
支持集群、虚机、网络、磁盘、数据库、应用、容器及业务等上百种监控指标与秒级监控,通过集群与虚机、虚机与应用、应用与资源统一建模,对各种指标智能关联分析,用户通过统一的告警入口和下钻找到问题根因。
2日志分析:分布式日志集中搜索与实时查看
将虚机上的应用、开源组件、系统等日志集中采集到数据库,用户通过日志管理快速找到应用实例日志,提供实时刷新、日志上下文查看、秒级搜索、日志下载等常用功能;
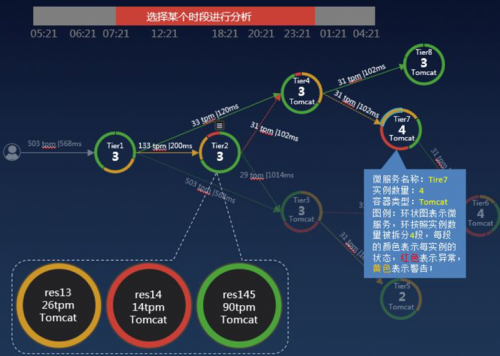
3应用拓扑分析:应用关系与异常一目了然、故障下钻
对应用健康状态可视化管理,包括应用运行状态、时延、错误、负载、依赖关系,包括数据库、缓存、消息中间件、NOSQL等各类开源组件。
华为云立体运维解决方案致力于打造全方位的云上整体运维方案,将云原生2.0运维的优秀实践以云服务的方式提供给外部客户,帮助客户应对云原生2.0场景下的各种运维难题。全面覆盖基础设施层、应用层、数据库或中间件等多维度监控指标,用户无需自建各种复杂的运维系统,也可即刻使用开箱即用的运维功能。
来源:至顶网云计算频道
好文章,需要你的鼓励


马斯克:SpaceX愿景是攀登卡尔达肖夫指数,我们必须去太空
刚刚,确实是刚刚。2026 年 6 月 12 日,SpaceX 以每股 135 美元在纳斯达克挂牌(SPCX),收于 160.95 美元,涨 19%,市值突破 2 万亿美元,史上最大 IPO。

西交利物浦大学联手香港中文大学:用“信息几何“给AI安全装上“地震仪“
这项研究提出用费舍尔信息矩阵谱范数衡量深度神经网络的内在脆弱性,无需发动对抗攻击即可评估模型稳健性,并推导了VGG、ResNet、DenseNet和Transformer的理论排名。

Andrew Yang:降低生活成本是下一个创业大机遇
前美国总统候选人杨安泽认为,AI浪潮将压缩薪资、取代就业,由此催生出一个新的创业机会——帮助普通人降低生活成本。他以马克·库班的平价药品公司为灵感,于去年创办了移动虚拟运营商Noble Mobile,以低价提供手机服务并与用户共享利润。杨安泽表示,住房、教育、食品、交通等基本生活领域都存在巨大机会,市场可以在政策失灵时发挥再分配作用,鼓励创业者突破AI泡沫思维,关注真实的民生问题。

南加州大学的AI研究团队如何让“模仿学习“变得更聪明——当AI导师的指导方式决定了学生能走多远
南加州大学提出DistIL方法,通过前向交叉熵目标和完整序列级梯度,解决AI自蒸馏训练中方向偏差与局部信用分配问题,在科学推理、编程和难题数学上均超越现有基线。
2020
12/23
18:04
分享
点赞

Andrew Yang:降低生活成本是下一个创业大机遇
PeopleSoft零日漏洞波及数百机构,数十GB数据遭窃
Broadcom强化Spring安全体系,全力防御AI驱动的网络攻击
Apple Silicon大幅提升Mac整体拥有成本优势
iOS 27 新增多语言键盘支持及输入体验全面升级
Protocol Buffers模式漏洞曝光:六大安全缺陷可导致远程代码执行
Gemini macOS 应用迎来图标更新及截图快捷键新功能
苹果年内将推出四款全新Mac机型,抢先了解详情
谷歌起诉涉嫌利用AI发送诈骗短信的中国网络犯罪组织
Linux基金会成立Tokenomics基金会以应对AI Token成本管理挑战
Anthropic Fable 5悄然降级引发网络热议,安全限制究竟该如何拿捏?
五色全线史低!AirPods Max 2 登陆亚马逊最低价
