
有了Serverless 企业不用再为挖掘数据价值而烦恼 原创
上世纪八十年代以前,信用卡行业判断消费者是否违约都是通过手工评估完成。八十年代以后,专业人员开始使用数据建立关于违约的概率模型,提高了评估的准确性并扩大了评估的规模。到了九十年代,美国十大信用卡中心之一Capital One公司的创始人Richard Fairbank和Nigel Morris意识到利用信息技术可以处理更加复杂的预测模型,向客户提供信用卡定制化服务。
现如今,数据的价值正在被各行各业所利用,例如电子商务企业可以提前预测客户需求,更加精准的进行备货;制造企业可以完善自身产品,生产出更加符合用户需求的产品。
这也要求IT运维需要满足基于海量运维数据对未来负载进行预测,提前规划资源,避免异常突发事件产生。所以企业也需要转变思路,因为原有的本地数仓和大数据平台,在数据汇聚与运算、特征工程与数据预处理、构建人工智能模型开发与推理环境、模型训练算力调度等方面都存在不同的限制。
现在,数据分析已经纷纷迁移到云上,而且在融入Serverless的理念后,云上分析可以提供更为极致的用户体验。
云上数据分析下一站Serverless
目前,将数据向云上迁移是企业持续在做的一件事,借助云上提供的数据存储、调用、开发、分析等功能可以更好地满足企业的数据分析、挖掘需求。
亚马逊云科技则可以提供这一揽子的服务,经过多年的技术演进,现在亚马逊云科技不但可以向企业提供数据分析的底层环境、算力调度、数据存储、环境配置、开发工具等等一系列数据分析基础设施,还基于自身技术实践积累,提供了Amazon Redshift数据仓库、Amazon EMR大数据分析服务、Amazon Kinesis流式数据处理框架,Amazon OpenSearch Service日志分析工具等。
与此同时亚马逊还将Serverless的理念带进了数据分析领域,用户在安全便捷进行数据分析的同时,无需配置资源,可以自由调度功能模块,让云上数据分析变得更加容易。
例如在低配置的终端上进行代码编写,在编写完数据处理与模型训练代码后,可以直接调用一个分布式计算任务,急速的完成数据处理与模型训练,任务结束后,资源就可以立刻释放,不造成一点浪费。换一个玩游戏的比喻就是,想玩3A(高成本、高体量、高质量的游戏)大作时,又不想买3080Ti显卡,如果使用一张serverless的显卡,只需要在游戏启动时付一些费用,就能获得游戏本身的计算量和灵活弹性的算力,关闭游戏时显卡就可以自动收回。
随着亚马逊云科技的技术创新,云上的数据分析也已经进入了Serverless阶段。当企业需要对海量数据进行深度挖掘、分析时,只需要三步,编写数据分析代码、提交任务(工作流)、debug任务(工作流),就可以启动运算流程、获得结果。
在这种“极简风”使用大数据的背后,是技术的成熟与强大的技术封装能力。如今,亚马逊云科技已经拥有100多种服务来支持任何数据湖用例,而且更多的无服务器就地查询与处理选项,可缩短获得结果的时间并降低数据洞察的成本。
为现代化数据战略铺平道路的智能湖仓
为了易于分析,企业开始建设数据湖将所有数据放在单一的存储库中,这样就可以基于标准的数据格式,以任何规模、低成本、安全地存储数据,便于在以后根据应用程序和最终用户的需求进行传输和转换,现在云中的数据湖正在成为许多企业的主流策略。
为此,亚马逊云科技制定了现代化数据战略,并与Serverless理念结合越来越紧密,帮助企业更好地利用数据,更敏捷的创新。亚马逊云科技推出了智能湖仓新方法,"智能湖仓"架构不仅打通湖与仓,还将湖、仓、专用数据存储整合为一体。
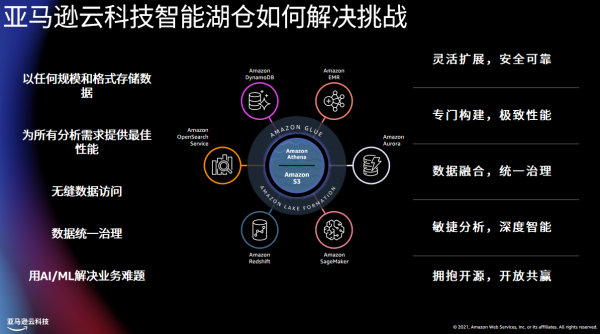
其实早在 2017 年,“智能湖仓”架构就已初具雏形。当时,亚马逊云科技发布了Amazon Redshift Spectrum,让Amazon Redshift具备了打通数据仓库和数据湖的能力,实现了跨数据湖、数据仓库的数据查询。如今“智能湖仓”基于Amazon S3构建数据湖,结合多种数据服务,形成了数据的“由内向外”,“由外向内”,“环湖运动”的数据移动方式,集成数据仓库、大数据处理、日志分析、机器学习数据服务。
正是了解到亚马逊云科技智能湖仓的技术优势,为加速创新并大规模实现数据使用,宝马集团将其本地数据湖迁移到由Amazon S3提供支持的数据湖,现在宝马集团可以每天处理来自上百万辆汽车的TB级遥测数据,并在问题影响到客户之前解决问题。为了更好地管理这些数据,宝马集团引入了“数据提供者”和“数据使用者”概念,从而提高了其软件工程团队的自主性和敏捷性。
“数据提供者”利用亚马逊云科技的数据分析服务(如 Amazon Kinesis Data Firehose、Amazon Lambda、Amazon Glue 和 Amazon EMR)来接收和转换数据。然后,“数据使用者”可以利用诸如 Amazon Athena、Amazon SageMaker、Amazon Glue和Amazon EMR之类的Serverless服务,运用这些数据。提供者和使用者均是在自己的账户中使用这些服务,只共享可由中央 API 控制的明确定义的接口,这有助于防止出现瓶颈。各数据层均存储在 Amazon S3 存储桶中,其架构已在 Amazon Glue 数据目录中注册。
现在亚马逊云科技智能湖仓架构中的服务基本上具备了Serverless特性,将Serverless能力扩展到分析引擎,实现自动添加或减少资源,提供恰到好处的容量,满足企业对任何规模的数据分析需求。企业用户再也不需要担心因为调整集群大小或为满足峰值容量而过度配置造成资源的浪费,进而节省时间并优化成本。企业还可以快速、轻松地开始使用亚马逊云科技数据分析服务,享受Serverless的自动部署、按需扩展和按需付费,不仅降低成本,还可以将数据分析服务扩展到更多用户,也降低了“门槛”。
Serverless改变数据分析规则的极简方式
在2021亚马逊云科技re:Invent上针对云原生数据分析服务重磅发布了云原生数据分析serverless选项和On-demand按需选项,分别是:
Amazon Redshift Serverless
Amazon Redshift Serverless ,让数据仓库更敏捷,支持在几秒钟内自动设置和扩展资源,用户无需管理数据仓库集群,实现 PB 级数据规模运行高性能分析工作负载。
Amazon MSK Serverless
Amazon Managed Streaming for Apache Kafka Serverless ,让流式数据接入与处理,支持快速扩展资源,简化实时数据摄取和流式传输,实现全面监控、移动甚至跨集群加载分区,自动调配和扩展计算和存储资源,让用户可以按需使用 Kafka。
Amazon EMR Serverless
Amazon EMR Serverless 让大数据处理更敏捷,用户无需部署、管理和扩展底层基础设施,使用开源大数据框架(如 Apache Spark、Hive 和 Presto)运行分析型应用程序。
Amazon Kinesis Data Streams on Demand
Amazon Kinesis Data Streams是一项无服务器服务,此次提供的on Demand版本可以让流式数据分析与实时数据场景搭建更敏捷。每分钟可以处理数 GB 的写入和读取吞吐量,而不必预置与管理服务器、存储,在成本和性能之间取得平衡且变得更加简单。
正如全球最大的制药公司之一罗氏制药(Roche)首席云平台和机器学习工程师 Yannick Misteli 博士所说:“Amazon Serverless可减轻运营负担,降低成本,并帮助罗氏制药规模化实践 Go-to-Market 策略。这种极简的方式改变了游戏规则,帮助我们快速上手并支持各种繁重的分析场景。”
有了Serverless,企业不用再为挖掘数据价值而烦恼。未来亚马逊云科技所倡导的现代化数据战略与适应云计算未来发展的Serverless理念也将深度融合,帮助企业更好地利用数据,更敏捷的进行创新。
来源:至顶网云计算频道
好文章,需要你的鼓励


一次实验室意外或将彻底改变计算领域
研究人员意外发现,标准MOSFET晶体管可同时模拟神经元和突触行为,形成"神经突触随机存取存储器"(NSRAM)。该技术仅需一至两个晶体管即可实现传统需数十乃至数百个元件才能完成的神经信号处理,且与现有硅基制造工艺完全兼容,良率达100%。未来有望应用于边缘AI及高能效神经形态芯片,长远或可挑战GPU地位。

Sakana AI与毕马威联手打造“咖啡经济沙盘“:当AI商人学会讨价还价,它们会做出什么选择?
CoffeeBench是Sakana AI与毕马威联合构建的多智能体经济基准测试,让六个AI企业在90天咖啡供应链模拟中自主经营,评估大语言模型的长期商业决策能力。

借鉴生态学模型评估AI风险的新方法
本文提出一种评估人工智能风险的新方法,借鉴生态学与演化论视角,从理论生态模型中推导出三项风险指标,涵盖种群模型与生态系统模型。研究旨在为AI治理策略提供量化工具,并对分析局限性及政策改进方向进行了深入探讨,为构建更科学的AI风险评估体系提供参考框架。

牛津大学让AI学会“物理直觉“:一个无需看视频就能预测物体运动的神经网络
牛津大学提出PHYSIFORMER,一种扩散变换器模型,通过三维网格顶点轨迹直接在世界坐标空间预测刚性与弹性物体的物理运动,一次性生成全序列轨迹,超越自回归基线。
2022
01/06
17:25
分享
点赞

“专业服务产品”,亚马逊云科技Marketplace(中国区)来了
Google 在 Colab Python 平台推出免费的 Gemini 驱动数据科学助手
DeepSeek狂飙,别让安全隐患成为“定时炸弹”
SAP Business Suite 重启计划引发用户关注
用MFA替代“password”,防御值加99%
Anthropic 经济指数 — 企业领导者必知的 10 大 AI 工作场所趋势
DeepSeek登场,企业级AI构建路径解析
TigerGraph 升级图数据库产品,实现更快部署速度和全新预配置方案
AI 数据公司主导 BestBrokers 最新独角兽企业榜单
2025年企业领导者必知的生成式AI技能与教育趋势
