
刷新中文命名实体识别SOTA,华为云论文入选国际顶会NAACL 2022
4月7日,自然语言处理领域国际顶级学术会议NAACL 2022(The North American Chapter of the Association for Computational Linguistics)公布论文入选名单,由华为云语音语义创新Lab多名研究者撰写的信息抽取论文《Delving Deep into Regularity: A Simple but Effective Method for Chinese Named Entity Recognition》被NAACL 2022 Findings接收,这代表着中文命名实体识别的最优结果 (SOTA) 被进一步刷新,更准确有效的实体识别将推动下游自然语言处理任务的进一步发展。
NAACL由国际计算语言学学会(ACL)主办,与ACL、EMNLP并称NLP领域的三大顶会,是人工智能的重要研究阵地。NAACL的录用十分严格,根据往年评选结果,只有不到30%的论文被接收。
作为自然语言处理中最经典、最基础的任务,命名实体识别一直受到广泛的关注与研究。近年来,中文命名实体识别任务上取得了明显进展,很多新的方法和框架被陆续提出,但往往忽略了实体词的内部组成。
对于中文命名实体而言,很多类别的实体都具有很强的命名规律性。比如说,以“公司”或者“银行”结尾的实体词,通常属于组织机构这一实体类别。因此,在《Delving Deep into Regularity: A Simple but Effective Method for Chinese Named Entity Recognition》中,华为云语音语义创新Lab的研究者提出用简单有效、规律性引导的识别网络来探究中文实体词中的规律性。
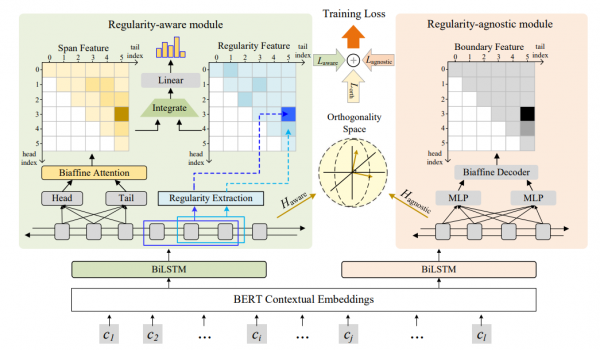
图1 规律性引导的识别网络
如图1,华为云研究者首先利用注意力机制显著地提取每个文本段的规律性,进而将这种表征文本内部的规律性的特征和通过Biaffine Attention提取的文本段特征结合起来,进行后续的实体识别。为了避免由于过度关注实体内部规律性导致的实体边界识别偏差,研究者们另外设计了一个与规则无关的模块来帮助模型更准确地识别实体的边界。
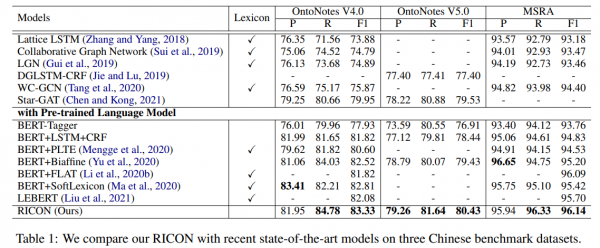
图2 中文数据集上的实验结果
华为云研究者提出的规律性引导的识别网络,如图2,在MSRA, Ontonotes4.0, 和Ontonotes5.0三个大规模中文实体识别数据集上都取得了SOTA的结果。同时,本文提出的方法不依赖于外部词典信息,并且F1值超过了目前所有使用词典信息的方法的结果。这充分说明通过研究实体词的内部规律性,研究者们提出了一个非常有效的网络结构。
不止在信息抽取方面,华为云语音语义创新Lab秉承开放创新、勇于探索、持续突破关键技术的精神,面向行业客户提供领先的语音语义AI能力,结合大量行业知识,推出知识计算等行业解决方案,打造业界一流的知识计算竞争力。截至目前,已在政务、金融、石油等多个行业进行了落地和实践,帮助客户实现AI落地与智能升级。
来源:业界供稿
好文章,需要你的鼓励



谷歌深度思维团队如何让机器学会像生物学家一样发现新药物
谷歌深度思维团队开发出名为MolGen的AI系统,能够像经验丰富的化学家一样自主设计全新药物分子。该系统通过学习1000万种化合物数据,在阿尔茨海默病等疾病的药物设计中表现出色,实际合成测试成功率达90%,远超传统方法。这项技术有望将药物研发周期从10-15年缩短至5-8年,成本降低一半,为患者更快获得新药治疗带来希望。

Google力推手机AI功能引发关注
继苹果和其他厂商之后,Google正在加大力度推广其在智能手机上的人工智能功能。该公司试图通过展示AI在移动设备上的实用性和创新性来吸引消费者关注,希望说服用户相信手机AI功能的价值。Google面临的挑战是如何让消费者真正体验到AI带来的便利,并将这些技术优势转化为市场竞争力。

哈佛和微软联手打造AI“预言家“:仅凭声音就能预测健康状况,准确率竟达92%
哈佛医学院和微软公司合作开发了一个能够"听声识病"的AI系统,仅通过分析语音就能预测健康状况,准确率高达92%。该系统基于深度学习技术,能够捕捉声音中与疾病相关的微妙变化,并具备跨语言诊断能力。研究团队已开发出智能手机应用原型,用户只需完成简单语音任务即可获得健康评估,为个性化健康管理开辟了新途径。
2022
04/13
17:32
分享
点赞

“4个9”韧性的背后,西云数据以技术与运营加速企业数字化创新
Google力推手机AI功能引发关注
Meta发布AI翻译功能,支持脸书和Instagram内容实时转换
HPE发布Nvidia Blackwell驱动的AI服务器,抢占AI市场需求
ISACA推出AI安全管理高级认证项目
谷歌推出智能体SOC系统提升安全事件响应速度
Lumen升级400GB数据中心连接基础设施助力AI发展
AI和流媒体推动,2030年面临"网络危机"
Pine64停产Pro手机转向RISC-V业务
日立Vantara将VSP One块存储扩展至Azure云平台
Finchetto光学数据包交换机:光无法存储的技术挑战与突破
Python开发者调查显示增长强劲,但基金会资金面临困境
