
英特尔至强6加持下的火山引擎,要降低大模型的应用门槛 原创

作者 | 金旺
来源 | 科技行者
在大模型继续上新的这个年底,12月18日,字节跳动火山引擎的豆包系列大模型也迎来了再次更新,一口气上新了15款大模型产品。
这其中,尤以豆包视觉理解模型最为亮眼,不仅拥有内容识别、理解推理、视觉描述等能力,还将价格再次打到了每千tokens 0.003元。
视觉大模型由此也或将迎来又一次大范围的普及应用。
就接下来的大模型产业落地来看,模型推理正在被提升到一个新高度,这对异构算力提出了更高要求。
在豆包系列大模型冬季发布会上,火山引擎联合英特尔展示了双方的合作成果,我们看到了基于AI PC的“扣子”,看到了企业级的AI方案。
我们也看到了,火山引擎联合英特尔对外发布了基于英特尔至强6性能核处理器的火山引擎第四代通用计算型实例g4il。
在英特尔至强6性能核处理器加持下,火山引擎的g4il云实例,也将再次降低大模型的应用门槛,为AI时代下的云服务提供了一个新选择。
01 火山引擎g4il实例,要降低大模型使用门槛
中国信通院《2024全球数字经济白皮书》统计数据显示,截至今年一季度,全球人工智能核心企业约有3万家,全球AI独角兽达到了234家,其中,中国则涌现出了71家AI独角兽企业。
就大模型而言,全球人工智能大模型数量为1328个,中国占比高达36%。
作为国内大模型领域的核心玩家,字节跳动先是在2023年8月上线了云雀大模型,后又在2024年5月正式推出了多模态大模型豆包,而如今的豆包已经成了日均调用量高达4万亿次的主流模型。
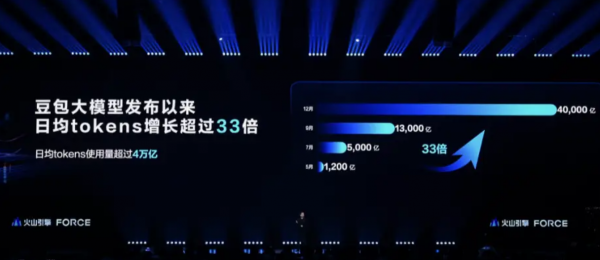
大模型的发展,进一步催生了对算力的高需求,尤其是在当下大模型进入产业落地阶段时,对于高性能异构算力也提出了更高的需求。
英特尔公司市场营销集团副总裁、中国区云与行业解决方案和数据中心销售部总经理梁雅莉指出,“英特尔至强6处理器正是为了适配数据中心异构多元算力需求而生。”

在大模型进入到应用落地阶段后,越来越多企业有了尝鲜大模型的想法和需求,为了满足这样的大模型测试、预研和轻量级大模型应用开发需求,火山引擎的g4il实例应运而生。
g4il实际上已经是火山引擎第四代通用计算型实例。
据火山引擎计算产品负责人王睿介绍,“g4il搭载了最新的英特尔至强6性能核处理器和火山引擎自研的DPU,实现了计算、存储和网络性能的全面升级,相比上一代产品,g4il在视频转码、Web应用、和数据库应用方面分别实现了17%、19%和20%的性能提升。”

此外,g4il还在以下几个方面得到了进一步提升:
首先,得益于英特尔至强6性能核处理器在CPU核数上的突破,g4il的单机CPU核密度相比上一代产品有了翻倍的提升,在算力的性价比上也有了很大的提升;
其次,通过采用火山引擎双单路创新服务器架构,g4il再次降低了整体的爆炸半径,有力地保障了产品稳定性;
第三,通过新增大包传输能力(Jumbo Frame)、机密计算能力(TDX),以及支撑最新云盘吞吐类型SSD,火山引擎进一步丰富了g4il实例的功能。
王睿指出,“英特尔在英特尔至强6性能核处理器上引入了MRDIMM技术,并新增支持AMX FP16指令集,更大的内存带宽和更强的矩阵运算能力,为AI推理加速提供了更优的底层基础环境。”
火山引擎的实测数据显示,相较于英特尔EMR CPU+DDR5内存,基于英特尔至强6性能核的g4il吞吐性能最高提升了80%,相较于单卡的A10和L20 GPU也有不小的优势。

在火山引擎FORCE原动力大会现场,我们在英特尔展区也看到了基于g4il实例的文生文的大模型演示,在现场演示过程中,当向PC上的大模型提问“什么是AMX时”,它可以在用户界面流畅地生成对应的答案。
据现场工作人员介绍,“这其实是在g4il实例上基于16个虚拟CPU核做7B模型的推理效果,这样的配置已经基本可以满足用户量较小、请求并发度较低的使用场景。”

在大模型成为全球焦点时,GPU开始被视为大模型的标配产品,实际上,作为通用算力的CPU依然可以满足不少大模型使用场景的需求。
据现场工作人员介绍,“基于g4il实例,企业用户只需要16个虚拟CPU核就可以做7B左右模型的推理验证工作,而当企业最终将这样的产品转化为真实落地产品时,可以再基于这一模型最终的用户数、并发量选配更高配的硬件规格,由此就可以降低用户使用门槛。”
对于一个百人规模的中小型公司,当需要在公司内部自研一个知识库问答系统时,甚至完全可以基于CPU、在g4il实例上来实现,这也将极大降低企业的大模型使用门槛。
而在生成式AI成为云时代标配,越来越多企业结合内部数据尝试使用大模型时,数据安全性也变得越来越重要。
对此,作为算力供应商的英特尔和火山引擎也深有体会。
02 如何消除大模型的数据安全隐忧?
2024年6月,在今年的WWDC2024上,苹果终于发布了他们的Apple Intelligence,高度重视隐私安全的苹果在WWDC2024上多次强调了用户隐私安全的重要性,并采用端云结合模式打造了Apple Intelligence。
数据安全问题并非只是大模型遇到的问题,相应的隐私计算技术也已经在近些年逐渐成熟。
如今成熟的隐私计算技术大致可以分为两个流派:
第一个流派是基于密码学的同态加密、多方安全计算、差分隐私、零知识证明等技术,这些技术完全依赖密码学方式实现数据可用不可见的保护。
不过,基于密码学的技术如今存在一个普遍问题,那就是会为企业带来较高的计算和通讯开销。
第二个流派是基于硬件、芯片构建数据安全处理的可信执行环境,此类技术又被称为机密计算。
据英特尔技术专家介绍,“机密计算得益于更低的损耗、更高的性能,更符合如今云计算时代的部署要求,正在成为云计算中构建数据可用而不可见的保护策略的主流技术方式。”
2019年,Linux基金会成立了机密计算联盟,该联盟的目标旨在定义机密计算标准,支持和推广开源机密计算工具和框架的开发,联盟创始成员包括英特尔、AMD、Arm、谷歌、红帽、阿里、华为、腾讯等来自全球的科技公司。
面对当下数据应用环境,机密计算主要致力于解决三大问题:
第一,数据机密性,确保用户数据在处理和使用过程中不外泄;
第二,数据完整性,确保待处理数据安全可靠、未发生篡改,确保计算结果的安全性和可信性;
第三,代码完整性,确保用户数据的程序代码安全可靠,未被植入恶意代码。
作为机密计算的创始成员之一,英特尔在机密计算领域一直都在进行着技术研发,并在将这些技术应用到至强处理器中。
英特尔最早是在第三代英特尔至强可扩展处理器中应用了SGX技术,后又在第四代和第五代英特尔至强可扩展处理器中应用了TDX技术。
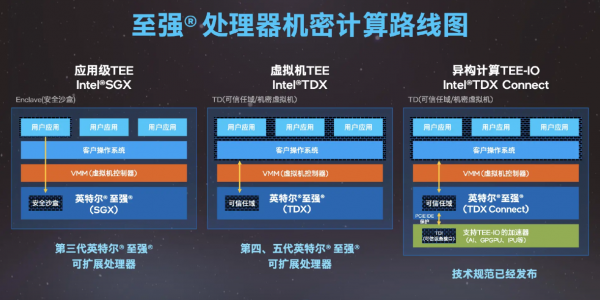
英特尔技术专家指出,“TDX技术构建的可信执行环境可以承载完整的用户虚拟化实例,只要用户的程序能跑在虚拟化环境里,都可以直接迁移到机密计算解决方案。”
而随着机器学习、大模型应用等高算力场景的不断涌现,用户数据有了在通用处理器和异构加速器之间进行协同计算的需求,英特尔又进一步推出了TDX Connect技术,这项技术可以使用户数据在异构加速场景中的计算得到机密性保护。
以大模型核心应用场景之一RAG为例。
RAG是检索增强生成模型,本质上是基于知识库、数据库的内容检索,大模型在生成内容时,参照数据库有针对性地增强生成结果,从而提升生成结果质量和准确性。
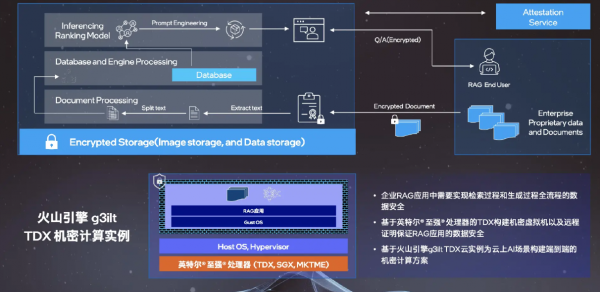
在这一应用场景中,由于行业知识库或企业知识库一定含有企业敏感信息,例如行业流程、企业流程,乃至技术文档。
用户在部署RAG服务时,对其是否会被窃取会存有疑虑,基于英特尔TDX构建的机密虚拟化实例,无论是RAG应用中的信息提取、数据库应用,还是模型生成流程,都可以在不改变应用程序中间框架前提下直接访问机密虚拟机,从而实现在云中隔离和保护用户在使用RAG部署过程中的数据安全。
实际上,火山引擎最近就基于英特尔TDX技术,推出了g3ilt TDX机密计算实例,这一云实例可以为云上AI场景构建端到端的机密计算方案。
我们在大会现场,也看到了g3ilt TDX机密计算实例的现场展示。

当然,基于英特尔至强6性能核处理器的火山引擎第四代通用计算型实例g4il同样支持TDX机密虚拟机,与此同时,针对云上AI场景,火山引擎打造了端到端安全解决方案。
王睿在大会上介绍称,“基于CPU和GPU硬件机密计算能力,火山引擎在固件、内核、虚拟化以及操作系统等方面做了深度调优,在机密计算云服务器上,火山引擎提供了机密容器、密钥管理、基线管理、远程证明和安全RAG等丰富的安全能力和服务,为AI应用当中的训练推理,前后端数据处理全场景提供安全保障。”
好文章,需要你的鼓励


Claude Sonnet 5 发布:编码、推理与工具使用能力全面提升
Anthropic于6月30日发布Claude Sonnet 5,相较前代Claude Sonnet 4.6在编程、推理、工具使用及知识工作方面均有显著提升。该模型可自主制定计划、使用浏览器和终端等工具,达到数月前需更大更贵模型才能实现的水平。安全评估显示其不良行为率更低。Sonnet 5默认开启自适应思维,采用更新的分词器,性能接近Opus 4.8但价格更低,现已面向所有订阅计划开放。

复旦大学、上海交大联手攻克机器人“眼手协调“难题:让AI真正理解动作背后的物理世界
复旦大学联合多机构提出A2World框架,通过210万条真实机器人轨迹进行动作条件化预训练,将学到的物理动力学先验同时迁移到仿真模拟和策略控制两个方向,在LIBERO和真实机器人任务上均取得当前最优表现。

AI高速扩张正悄然考验电网承载极限
人工智能基础设施的快速扩张不仅带来总用电量激增,更在改变电网的运行特性。AI训练任务高度同步、计算密集,推理任务则分散且难以预测,两者均可在极短时间内造成电力需求骤变。数据中心的地理集中分布进一步加剧局部电网压力。现有监管框架多基于稳定工业负荷设计,难以适应这类新型需求。专家指出,电网规划需从关注总能耗转向关注需求波动性与同步效应。

同济大学研发的“地空协作机器人“:如何让无人车和无人机在黑暗隧道里默契配合?
同济大学研发的FLISP系统,让无人车与无人机在水电隧道中无需建图、仅靠激光雷达实时协作导航,规划延迟仅7毫秒,成功率100%。
2024
12/20
17:40
分享
点赞

AI高速扩张正悄然考验电网承载极限
福特对AI失望,重新雇用350名经验丰富的工程师
首批四家云服务商加入CISPE欧盟云主权认证计划
2026 Eurobike 展会:最值得关注的电动自行车与新奇产品盘点
联想Legion 7i Gen 10游戏本评测:颜值在线,性价比存疑
杀毒软件已不够用?全面了解现代网络安全防护
大语言模型助力机器人理解模糊指令并聚焦关键细节
MIT AI与社会论坛:探讨AI对就业、民主等领域的深远影响
麻省理工学院新芯片助力微型机器人穿越复杂环境
扎克伯格承认Meta智能体AI进展未达预期
Rust 1.96 正式发布:引入全新 Range 类型体系
AI驱动的内存危机:苹果的困境也是所有人的困境
