
你见过这个版本的龙生九子吗?
在《这届超算大会展示了哪些黑科技?》一文中,提到过专门用于GPU/协处理器(下文中简称GPU或者加速器)计算的DellPowerEdge C4130服务器平台。戴尔C4130可以保证在1U空间内支持4块全尺寸GPU卡,大大提升了系统的计算密度比。中国有句话叫做,龙生九子,各有不同,这句话放在C4130身上特别的贴切。这款产品拥有九种形态,可以适应不同的应用需求。

同样我也提到过C4130中可选96 lane PCIe 3.0Switch,引入它之后该平台的GPU/协处理器卡连接方案达到9种之多。这样设计的目的,或者说对用户的价值是什么呢?
我们先列出一些值得关注的方面,下文中将围绕它们进行衡量:
1、CPU to GPU/协处理器带宽;
2、GPU to GPU直连访问(GPUDirect),
池化or拆分;
3、网络I/O带宽限制;
4、散热、功耗和成本。
Xeon CPU PCIe
通道限制及解决方案
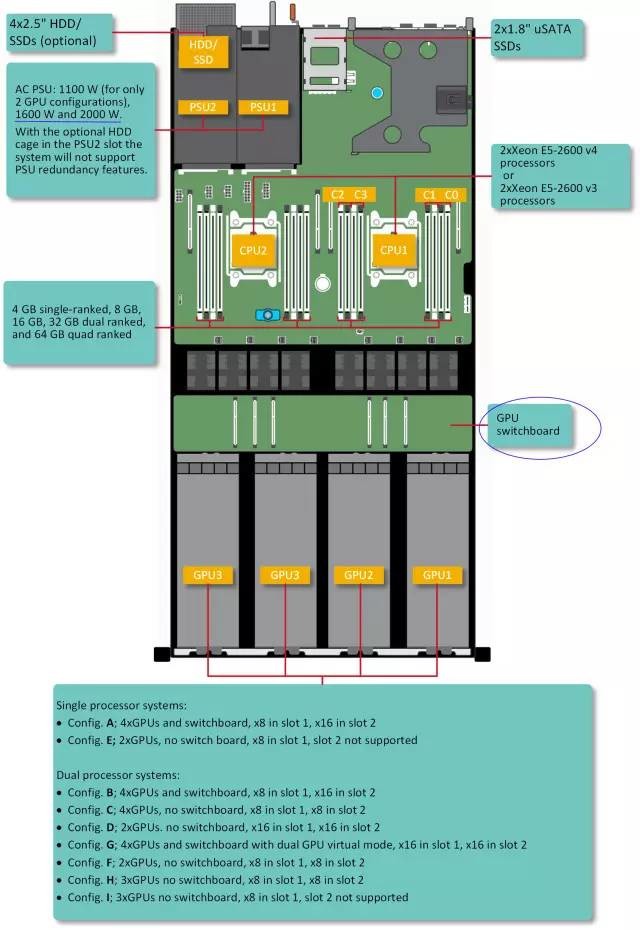
蓝色标注部分包括“GPU switchboard”和电源功率,注意只有1600W和2000W电源模块可以支持4个GPU/协处理器卡。
上图引用自《Dell PowerEdge C4130 Owner's Manual》,里面明确标出了CPU、GPU等组件在机箱中的位置,以及从A到I共9种连接方案,除了CPU和GPU的数量、有没有PCIe Switch板之外,还有一点受影响的就是服务器PCIe扩展槽。
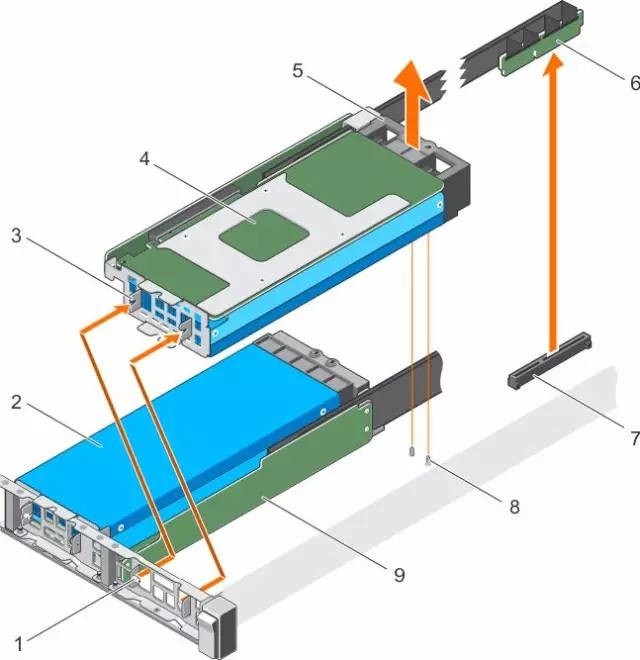
这个示意图是GPU卡的安装。用于高密度服务器的GPU都是被动散热方案,系统风扇和风道设计就很重要了。

GPU switch board
6个插槽的作用我会在后面讲
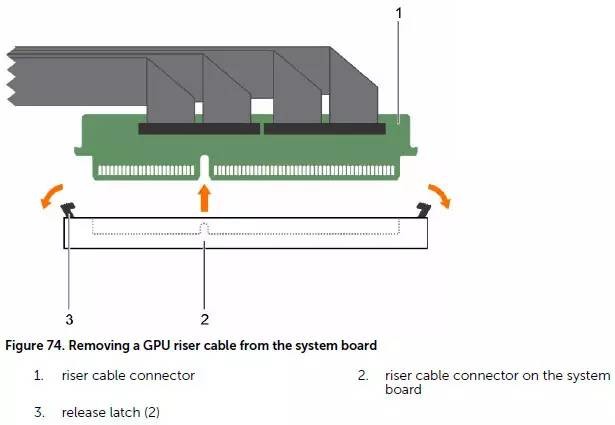
这个转接板的金手指不是标准的PCIe定义,下面我们来看看它的连接示意:
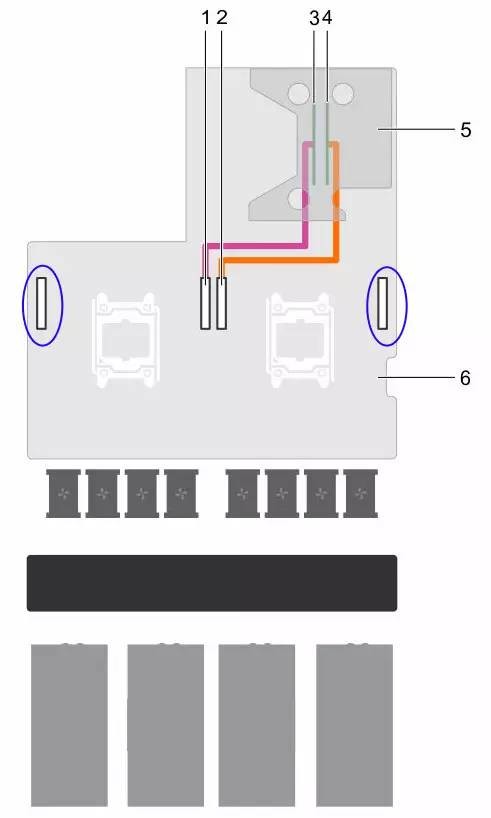
PowerEdge C4130主板上有4个PCIe x16连接器,它们都不是直接插设备的。中间2个可以选择选向后连接其它PCIe扩展卡,位于两侧的我在这个示意图里用蓝色标出。
我们知道每颗Xeon E5 CPU提供40 lane PCIe 3.0通道,如果提供2个x16用于全速连接GPU,不做专门设计的话,位于PCIe扩展卡的位置只能提供x8的带宽。由于C4130的HPC用途和计算密度,有时需要配置双端口56Gb/s Infiniband,以及100Gb/s EDR IB和Intel Omni-Path高速网卡。因此才会有上面的连接选项。
在这种情况下CPU自身的PCIe控制器信道数开始不够用,PCIe Switch被引入,同时GPU之间的直接通信效率更高。
配置A&B;:GPU点对点,重加速器轻I/O
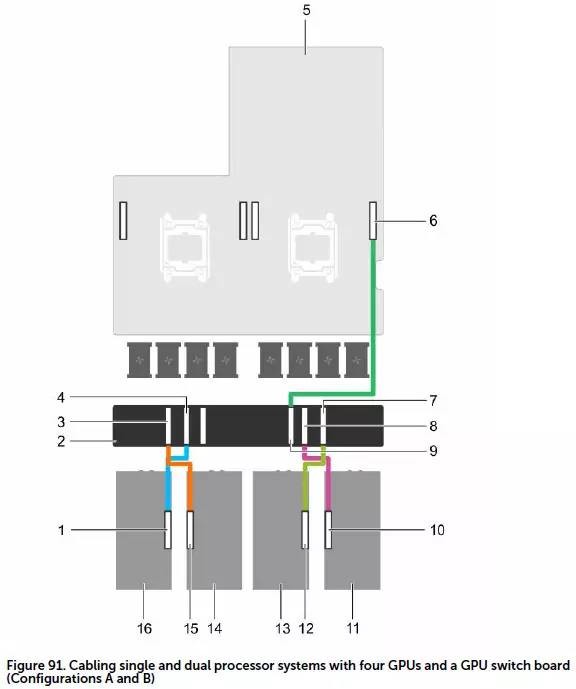
如上图,配置A是将单Xeon E5 CPU的一个PCIe x16连接到GPU switch board,然后再用后者连接4个GPU,同时CPU 1的另一个PCIe x16插槽用于提升其它扩展卡的带宽。在同等密度下经济性最好,每个GPU/协处理器到CPU之间的平均带宽虽然不算高,但GPU之间可以通过GPUDIRECT技术直接高效通信。
配置B是在这个基础上增加了一颗CPU,保持PCIe Switch和GPU的池化连接方式,与配置A相比提高了CPU计算能力和内存支持。
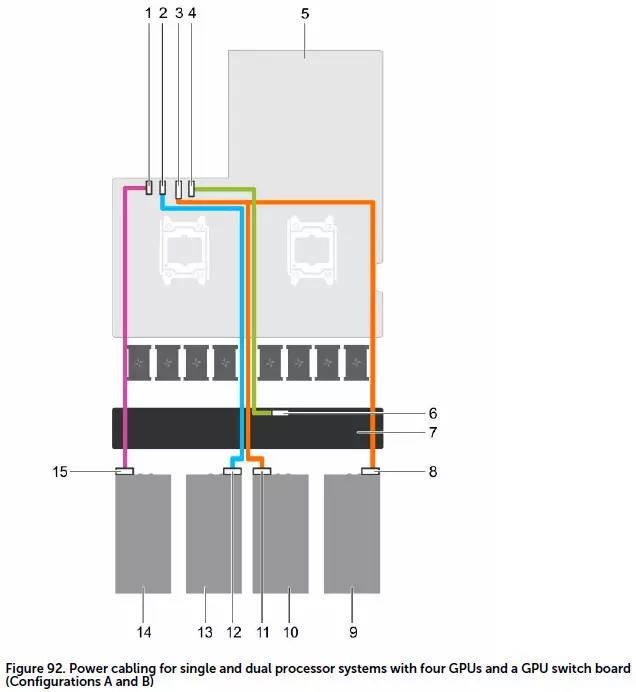
这张示意图是PowerEdge C4130的GPU供电连接,四条线缆都是从电源与主板连接的位置附近引出。如果是没有GPU switch board的配置,那条浅绿色的就不需要了。
配置C:最大加速器&CPU;密度,高度均衡架构

配置C也是一种比较常用的方案。不需要增加GPU switch board,而且CPU与GPU之间还都是PCIe x16全速连接。它对4个GPU的支持为拆分(split)模式,如果说尚有缺憾之处,就是必须配2颗CPU,并且后面2个常规PCIe扩展槽位都只有x8带宽。正是因为每种方案各有取舍而非十全十美,所以C4130才提供了这么多选择。
配置D:平衡加速器密度和高性能I/O
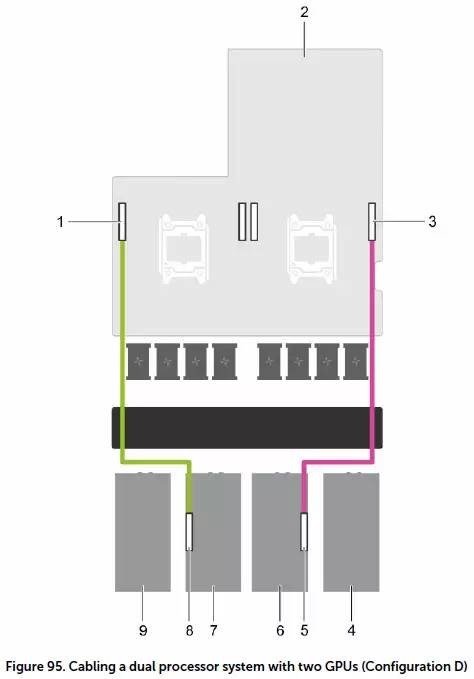
配置D只安装了2个GPU/协处理器卡,所以每CPU都剩下1个PCIe x16,这样在不用GPU switch board的情况下后面的2个扩展卡就都可以跑到全速。能够充分发挥InfiniBand EDR高速网卡的带宽。
配置E/F:低密度Scale-out电源散热需求放松
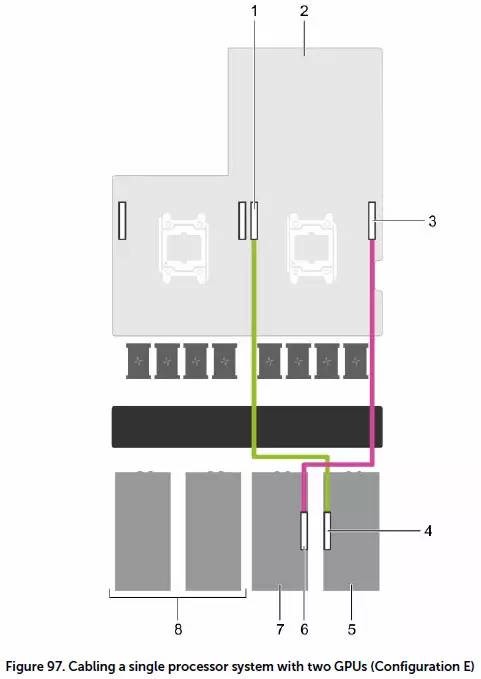
配置E针对入门级GPU密度环境,单一CPU不用switch board PCIe x16直连两块GPU卡。因为没有插第二个CPU,这时PCIe扩展卡只能支持1块x8带宽的。该配置以相对较低的功耗换来了良好的Scale-out能力,因为每台PowerEdge C4130的供电和散热需求降低了,单位机架空间内就可以多放几台。
配置F是在配置E基础上增加第二颗CPU,除了前面提到过的好处之外,就是第二个x8 PCIe扩展槽也可以使用了。这里CPU2上的PCIe也没有使用x16宽度连线,估计是为了保持其入门级定位。
配置G:最大计算密度均衡I/O方案

配置G一方面将96 lane PCIe Switch交换板充分利用(拆分成2个池),共2个上行to CPU + 4个下行to GPU,同时常规PCIe扩展槽位还能提供2个x16支持。是一种最大化加速器和CPU密度的高度均衡方案。
配置H&I;:重VDI(图形)工作负载方案
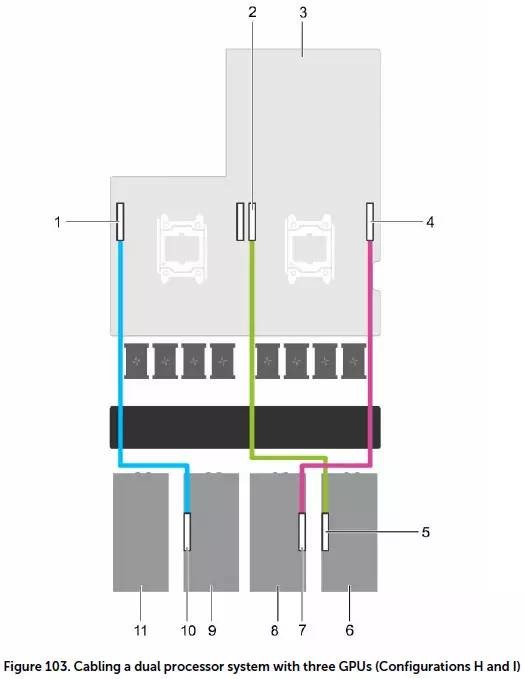
配置H和I是用一颗CPU的2个PCIe x16直连2块GPU卡,另一颗CPU连接另1块GPU,同时提供2个或者1个常规PCIe x8扩展槽位。该方案的GPU/CPU核心配比为图形密集型VDI应用进行了优化,专门针对NVIDIA Grid K1 GPU设计。
从灵活性到HPC的进一步咨询
大家知道GPU服务器面向一些特定应用领域,不如常规服务器那样标准化。起初我以为只需要考虑密度和PCIe连接带宽,而通过对Dell PowerEdge C4130的学习之后,却发现里面还有这么多门道。
对异构HPC有需求的用户,如果还不确定什么样的配置最适合自己,可以找HPC方面的专家顾问进一步咨询。他们可能会有不少同行业应用的经验分享给您哦 ( ̄︶ ̄)


来源:ZDNet云计算频道
好文章,需要你的鼓励


Visa、Stripe等140余家机构联合推出Open USD稳定币,剑指Tether
超过140家金融、支付及科技公司,包括Visa、Stripe和贝莱德,联合支持推出名为Open USD(OUSD)的新稳定币,直接挑战市场领导者Tether和Circle。OUSD由独立机构Open Standard LLC运营,主打零费用、无限额铸造与赎回,且储备收益大部分归合作伙伴所有,而非由发行方独占。Mastercard、美国运通、谷歌、Shopify、Coinbase等巨头均已加入。Circle股价在消息公布后下跌约13%。

当望远镜遇上“翻译官“:加州大学河滨分校等机构揭秘AI如何“读懂“星系照片
这项研究系统比较了四种AI图像分词策略在640000张星系图像上的表现,发现重建质量与物理属性预测能力之间存在根本性解耦,为天文基础模型的分词器选择提供了实验依据。

Anthropic发布Claude Sonnet 5大语言模型,编程能力与安全性双升级
Anthropic正式推出中端大语言模型Claude Sonnet 5,其编程能力在SWE-Bench Pro和Terminal-Bench 2.1两项基准测试中分别提升5.1%和13.4%。该模型具备更强自主性,能主动核查输出结果,并在抵御恶意请求和提示注入攻击方面表现更优。Sonnet 5将成为Claude免费版和Pro版的默认模型,定价为每百万输入token 3美元。此外,此前因美国出口管制而暂停推出的Mythos 5和Fable 5模型,管制已解除,将于近期恢复访问。

阿里Qwen团队教机器人“举一反三“:当AI大模型遇上机械臂,泛化能力的秘密在哪里?
阿里Qwen团队研究如何将大模型的规模化训练思路迁移到机器人操作领域,通过统一多机器人表示与38100小时数据预训练,让机器人在陌生场景和陌生机型上也能完成复杂操作任务。
2017
01/22
10:05
分享
点赞

Visa、Stripe等140余家机构联合推出Open USD稳定币,剑指Tether
Anthropic发布Claude Sonnet 5大语言模型,编程能力与安全性双升级
Wayve以85亿美元估值启动8500万美元员工股权流动计划
遗留系统与数据缺口制约香港企业财资中心发展
美国要求OpenAI限制其最强大AI模型的访问权限
两党州长达成共识:数据中心建设费用不应转嫁给普通用户
北美电网夏季压力暂缓,但容量危机隐患未除
为270万人守护饮水安全:莫卡辛水电站发电机组更新改造全记录
加州最大光储项目Eland:清洁能源未来的范本
AI音乐视频生成:2026年十款自动化创作工具盘点
欧洲AI安全与网络滥用桌面推演的核心洞察
Rivian R2激光雷达实车曝光,外观设计优于同类车型
