
业内实测:基于SkyLake的14G有多强悍
“一只南美洲亚马逊河流域热带雨林中的蝴蝶,偶尔扇动几下翅膀,可以在两周以后引起美国德克萨斯州的一场龙卷风。驱动整个行业技术变革的触发点可能只是一个小小的组件,比如NVMeSSD。当采用PCIe x8通道的NVMe SSD带来100万+ IOPS,终于把CPU变成了瓶颈,一场主流2U服务器风暴正在登陆中。”
NVMe SSD的性能有多高?常见PCIe 3.0 x4通道的NVMeSSD,4KB随机读取性能接近80万IOPS已经不是新鲜事,采用PCIex8通道的NVMeSSD更是可以获得100万+的IOPS。
风暴前兆 当CPU成性能瓶颈
性能高也有“烦恼”,比如我们突然发现CPU的性能不够了——硬盘时代,大家常说存储是系统的性能瓶颈,经过SATASSD的过渡,PCIe到NVMeSSD,终于把CPU变成了瓶颈。提高CPU性能有两大手段:高主频与多内核。不管用哪个手段,最终都反应为能耗的一路攀升。今年7月刚刚发布的至强可扩展处理器(XeonSP)功耗已经突破200W,比上一代的至强E5 v4高出近50%,对普遍采用风冷散热的通用服务器而言,结构设计的功力空前重要。
并且,NVMeSSD的性能发挥的前提是高速的PCIe通道。一个U.2接口的NVMeSSD需要PCIex4,而每个至强SP提供48条PCIe3.0通道,比前代提高20%。双路至强SP服务器共有96条PCIe3.0通道,全部用上正好支持24个U.2的NVMeSSD,刚好对应主流2U服务器的24个前置2.5英寸盘位设计。即使考虑到PCH、网卡以及其他必要组件也要占用PCIe通道,实际上能支持的NVMeSSD数量不会有那么多,但CPU也未必吃得消啊……
考验服务器设计能力的时候到了,尤其是U.2NVMeSSD的加入。一方面2U标准机箱内的高性能(通常意味着高能耗)组件更多,需要更好的散热设计;另一方面,如何去兼顾NVMeSSD的性能,同时继承双路服务器“多面手”的优良传统?
掀起主流2U服务器风暴
新处理器的推出必然带动新一轮服务器升级,在英特尔正式发布至强SP家族的当天,戴尔也同步推出了基于该系列处理器家族的第一波14G服务器,包括肩负更新主流2U市场重任的PowerEdgeR740/R740xd。在2017戴尔科技论坛(DTF)举办之前,企事录实验室获得了一台配置诚意满满的DellPowerEdgeR740xd服务器:双路XeonGold6130处理器(8张图速览新至强:Skylake架构、外貌与型号)、384GBDDR4-2666内存,双M.2SSD配置的BOSS(BootOptimizedStorageSolution,优化启动存储方案)卡,(支持RoCE的)双端口25GbE网卡,以及最重要的4块U.2NVMeSSD。

乍一看,作为新一代的R740xd跟以前的13G服务器好像没什么区别,但细看却大有不同。先看前面板,注意最右4块盘,就是高性能的U.2规格NVMeSSD,来个特写:

4块800GB的U.2 NVMeSSD,加上内部的XeonGold6130处理器和384GB内存,让我们充满期待。

R740xd内部照,尾部的两个PCIe×16插槽上各连接了一个扣着银色散热片的PCIeCard,这实际上是连接前面板U.2NVMeSSD的PCIe扩展卡。

这是PCIe扩展卡的核心——基于PLX的PCIeSwitch芯片,采用PCIe3.0x16接口,分为AB两个端口,每个端口是PCIex8规格,支持两块x4的U.2 NVMeSSD。因此一块卡可以全速连接4块U.2 SSD。
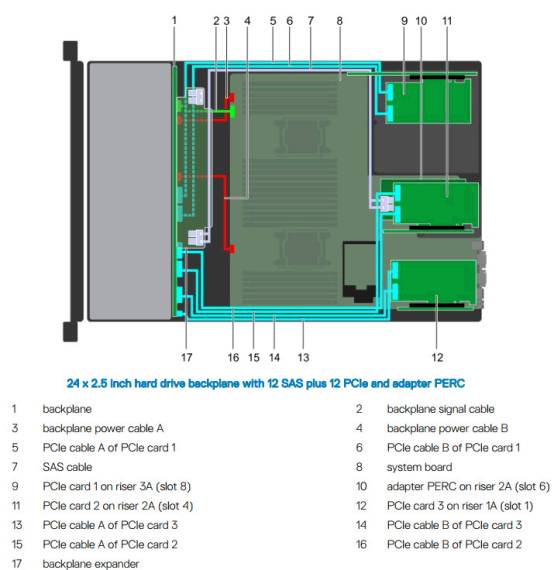
DellPowerEdgeR740xd服务器中的U.2NVMeSSD连接示意图,最大可支持12个U.2SSD,或者最大24块SATA/SAS SSD或者HDD,亦或两者按比例混插。
再看看R740xd中的PCIe通道分配情况:
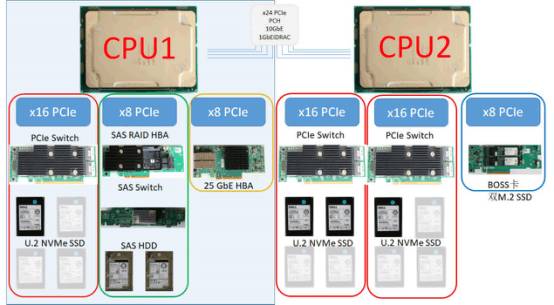
根据企事录手里的这台戴尔 R740xd服务器的配置,我们画了如上的示意图。
CPU1/2分别提供不同的PCIe扩展槽(其余的PCIe通道被PCH、板载网卡等周边设备所使用):
·红色框内的是将处理器原生的16X PCIe桥接成4个x4的U.2通道,一共可以支持12个U.2设备,图中的4块U.2是我们经过测试后优化布置的4块800GB的U.2 NVMeSSD,灰色的是可以扩展的空位;
·绿色框是一块PCIex8的H740p SAS RAID卡,通过磁盘仓背板的SAS Switch提供24个SAS/SATA盘位支持;
·橘色框是新一代的25GbE网卡,同样也是PCIex8的设备;
·蓝色框是戴尔14G服务器中所提供的一个全新设计的BOSS卡,在一个PCIe板卡上提供2个M.2(SATA) SSD,支持RAID1,用于提供高性能、低故障率的系统盘服务。
由此可见,尽管双路平台R740xd有96条PCIe通道,但仍有不够用的感觉,除了BOSS卡(x4)、H740pSASRAID卡(x8)、25GbE网卡(x8)、PCH和板载网卡(10GbE和1GbE)之后,也仅给高速的NVMeSSD留下了48条PCIe通道可供使用,恰好满足12个NVMeSSD所需要的PCIe通道数。(选择PCIe卡桥接U.2相比板载U.2接口,灵活性更好。在服务器上将更多的PCIe总线留给扩展性更好的PCIe插槽,会方便用户的使用。)
在企事录实验室中的这台 Dell PowerEdge R740xd服务器配备了4块三星PM1725系列的U.2NVMeSSD:

DellPowerEdgeR740xd服务器中所使用的NVMeSSD,800GB容量,属于三星PM1725系列:最大3.1GB/s带宽,4k随机读写IOPS分别为75万和12万。
突围200万TPM魔咒
数据库类应用是目前最能充分发挥NVMeSSD性能优势的企业应用场景之一,尤其是关键业务数据库。因为NVMeSSD具有很好的单位IOPS成本,又具有数据库类应用所需要高性能和低延迟。同时考虑到R740xd服务器配备了两颗英特尔XeonGold6130处理器和384GB内存,具有很好的性能,所以企事录实验室首先部署了一个单实例的Oracle数据库环境,以此来评估这台PowerEdgeR740xd的性能表现。
在构建好Oracle 12c数据库之后,考虑到R740xd中配备了384GB的内存,而4块NVMeSSD的容量之和为3.2TB,为避免大内存容量导致的数据库I/O性能虚高,企事录在创建数据库过程中稍微限制了Oracle所能使用的内存容量,即将SGA的内存容量限制为64GB,同时写入200GB的测试数据。稳定运行1小时之后,获得Oracle数据库性能:
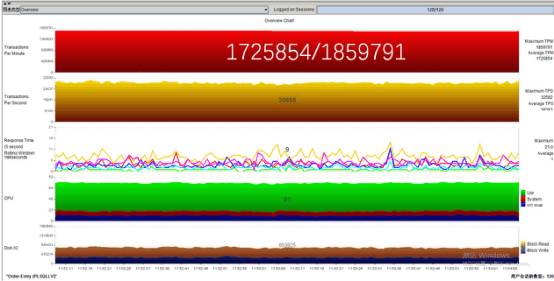
在4块NVMeSSD下,配备XeonGold6130处理器的R740xd服务器获得了172.5万的平均TPM,峰值TPM超过186万,接近200万TPM;平均TPS接近3万左右,峰值TPS超过3.2万,且平均响应时间仅为3ms。
单纯就性能而言,平均3万TPS的Oracle数据库性能已经接近了某些全闪存阵列的性能水平。但结合企事录实验室以往的测试经验来看,计算能力应该达到了瓶颈,毕竟Oracle数据库也是非常消耗计算能力的应用,从上图可以看到,R740xd的CPU占用率已经超过了80%。
尽管黄金版的6130处理器在至强SP家族中只处于中上游水平,但其结合NVMeSSD构建的单实例Oracle数据库性能已经接近上一代顶级至强E5-2699 v4处理器的性能。200万TPM对于双路服务器而言,似乎是一个不过逾越的难关,但在新一代Xeon处理器中却有望破除。

上图是在Oracle数据库测试过程中,从(OracleLinux7.4)操作系统上获得的截图,虽然有些核心的利用率为50%左右,但有些核心已经高达90%,从最上面的CPUHistory曲线来看,已经有部分核心的利用率接近100%,这应该是Oracle数据库性能无法进一步提升的瓶颈所在。
为了证实4块NVMeSSD并未达到性能瓶颈,企事录实验室利用Oracle数据库本身的命令行脚本测试了在1块SSD和4块SSD情况下,Oracle数据库随机读取的性能情况:

图上为1块NVMeSSD情况下,Oracle数据库的随机读取性能,接近42万IOPS,带宽在3.3GB/s左右,这基本是单个U.2版本PM1725的极限性能;图下则为4块NVMeSSD情况下,Oracle数据库随机读取性能高达170万IOPS,带宽约13GB/s。简单推算,随着NVMeSSD的增加,其IOPS性能是线性增长的。
这一测试结果基本可以确定并非NVMeSSD出现瓶颈,接下来,企事录实验室分别针对1、2、3块NVMeSSD下的Oracle数据库性能进行了测试,并结合4块NVMeSSD下的Oracle数据库性能:
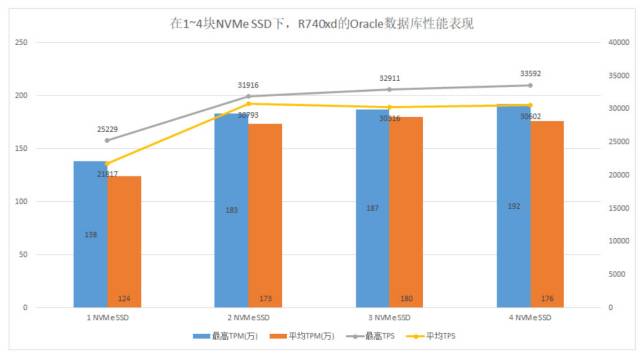
分别在1~4块NVMeSSD作为数据库存储下,基于R740xd服务器构建的Oracle数据库性能表现,可见在2块NVMeSSD情况下,Oracle数据库已经获得最高性能,随着NVMeSSD的增加,其性能表现并没有明显变化。究其原因,即这台R740xd的两个XeonGold6130处理器计算性能达到上限,如果使用更高计算能力的处理器,Oracle数据库的性能还有提升的空间。
来源:至顶网云计算频道
好文章,需要你的鼓励


AI时代Chiplet设计中不可或缺的可观测性层
在基于Chiplet的架构中,可观测性正成为系统设计的关键缺失环节。多位半导体行业专家指出,AI可从硅层遥测数据中挖掘价值,但前提是架构须提供一致的检测手段、近传感器数据压缩及可编程采集能力。专家们强调,多供应商Chiplet生态系统需要标准化、安全的遥测模式,以实现跨芯片、封装和互联域的故障定位,同时保护敏感运营数据。目前,AI在遥测分析阶段已展现出显著价值,但可观测性的扩展本质上仍是架构问题。

当望远镜遇上“翻译官“:加州大学河滨分校等机构揭秘AI如何“读懂“星系照片
这项研究系统比较了四种AI图像分词策略在640000张星系图像上的表现,发现重建质量与物理属性预测能力之间存在根本性解耦,为天文基础模型的分词器选择提供了实验依据。

从传统CRM迈向智能化客户互动的转型之路
生命科学企业在全渠道战略和AI平台上投入巨大,但成效往往不尽如人意。问题根源不在于技术本身,而在于组织架构、数据治理和工作方式未能同步演进。许多转型项目止步于试点阶段,原因是各部门数据孤立、职责不清。要实现从传统CRM向智能互动的真正转型,企业需优先建立统一的数据基础和跨团队协作机制,并将AI能力嵌入日常工作流程,而非将其视为独立模块。

阿里Qwen团队教机器人“举一反三“:当AI大模型遇上机械臂,泛化能力的秘密在哪里?
阿里Qwen团队研究如何将大模型的规模化训练思路迁移到机器人操作领域,通过统一多机器人表示与38100小时数据预训练,让机器人在陌生场景和陌生机型上也能完成复杂操作任务。
2017
09/11
11:37
分享
点赞

从传统CRM迈向智能化客户互动的转型之路
Wonder与Zipline合作,无人机送餐服务将于2027年在德克萨斯州上线
无人机卫星通信突破:轻量化终端助力野火响应
Google承认AI发展速度已超过电网脱碳速度
欧盟拟将AWS和Azure列为数字市场"守门人"
隆湫资本完成对「蓝芯算力」Pre-B轮超3亿元独家投资
Visa、Stripe等140余家机构联合推出Open USD稳定币,剑指Tether
Anthropic发布Claude Sonnet 5大语言模型,编程能力与安全性双升级
Wayve以85亿美元估值启动8500万美元员工股权流动计划
遗留系统与数据缺口制约香港企业财资中心发展
美国要求OpenAI限制其最强大AI模型的访问权限
两党州长达成共识:数据中心建设费用不应转嫁给普通用户
