
有一本书,只有它能读
“毫不夸张的说,人类每一次进步都由计算驱动在精准医疗的范畴里,每个人都是一本由遗传密码写成的书,字数有3乘10的9次方之多,装订成书,有四十层楼那么高——尽管这本书目前只有3%被读懂,然而由计算所驱动的“一小步”,已经令某些特定癌症的患者“绝处逢生”;飞速发展的高性能计算,将辅助医学专家们加速破译人体遗传密码,直到有一天,医疗将不再等同于治疗,而真正成为维护健康的天使之翼!”
就眼前的医疗体系而言,仍然是以病人为对象,以诊断治疗为目的,由医院、医生和医药组成“三医联动”的概念化医疗体系,为患者提供诊治服务。
而随着精准医学的发展,可以通过对大数据的分析,在尚未患病的时候就全面了解和掌握的评测对象的健康状况,预测未来发展趋势,并通过更加主动的干预手段来维护健康状况。
精准医疗的一小步
所谓精准医疗(Precision Medicine),是以个体化医疗为基础、随着基因组测序技术快速进步,以及生物信息与大数据科学的交叉应用而发展起来的新型医学概念与医疗模式。
其本质是通过基因组、蛋白质组等组学技术和医学前沿技术,对于大样本人群与特定疾病类型进行生物标记物的分析与鉴定、验证与应用,从而精确寻找到疾病的原因和治疗的靶点,并对一种疾病不同状态和过程进行精确分类,最终实现对于疾病和特定患者进行个性化精准治疗的目的,提高疾病诊治与预防的效益。
信息技术将成为推动精准医疗发展的强大动力,并为基因测序技术和生物医学分析技术带来革新与进步。高性能计算在商业领域的普及应用,以及大数据分析技术,为精准医疗的发展提供了广阔的想象空间。
这本“书”要这样来读
每个人约有1万亿个细胞,每个细胞里面都有23对染色体,这些染色体中包含的DNA由ATCG不同碱基序列构成,这些基因序列就是破解人类遗传信息奥秘的钥匙,基因测序工作就是要通过大规模的计算分析从海量的数据信息中辨识载有的基因及其序列,最终获取遗传信息。
目前基因测序在临床上的应用主要有两类:一类是针对普通人的疾病筛查,通过测定已知的与某种疾病相关的基因序列位点,来推断其未来罹患该种疾病的概率;另一类是针对癌症等致命性疾病的伴随诊断,通过测定某些特定的基因序列位点,在一系列的药物或治疗方案中找到对特定患者最为有效的药物或方案。
基因测序技术应用需要对海量、复杂、多变的数据进行分析计算,因此需要高性能计算机来进行基因数据的统计和分析。基因测序分析对高性能计算机的计算性能、内存容量、数据带宽等要求很高,同时还必须支持完善的基因测序分析工作流。
基因测序流程如下图:

测序数据分析流程(以全基因组分析为例)如下图:
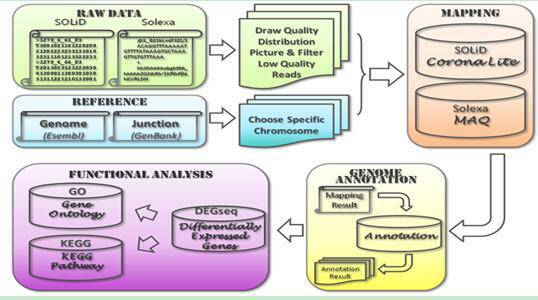
实验仪器测量数据处理和分析,首先通过实验仪器对生物分子进行测量,使用一些后处理软件对原始的大量数据进行处理和分析。比如对DNA分子进行研究的Illumina 公司的测序仪Genome Analys,HiSeq 2000以及相应的后处理软件GAPipeline等;ABI公司的测序仪Solid3、Solid4以及后处理软件Bioscope。然后对序列数据进行同源及相似性搜寻、比对、序列分析、遗传发育分析等,应用软件数量巨大,各种软件在同源性分析算法上各有特点,通过基因测序获得只是ATCG四种不同碱基的组合,还不是直观的结果;要将测序结果进行解读,还需要在高性能计算机上进行大量的演算和分析。
在高性能计算机中计算时需要多个软件协同工作,一步一步完成数据的分析,最终才能呈现出可读的结果。通常要得到最终的结果,要经过样本的采集、提取组织DNA、进入测序仪测序,随后进入计算机对测序数据进行标准化的计算,最终进行数据的分析、核验。
在短短十几年间,已经形成了多个研究方向,其中与高性能计算相关的主要研究重点如下:
序列比对:序列比对(Sequence Alignment)的基本问题是比较两个或两个以上符号序列的相似性或不相似性。
从生物学的初衷来看,这一问题包含了以下几个意义:从相互重叠的序列片断中重构DNA的完整序列。在各种试验条件下从探测数据(probe data)中决定物理和基因图存贮、遍历和比较数据库中的DNA序列、比较两个或多个序列的相似性、在数据库中搜索相关序列和子序列、寻找核苷酸(nucleotides)的连续产生模式、找出蛋白质和DNA序列中的信息成分。
在序列对比的过程中将会产生巨量的数据,这对存储系统带来了大规模的挑战。如下图:
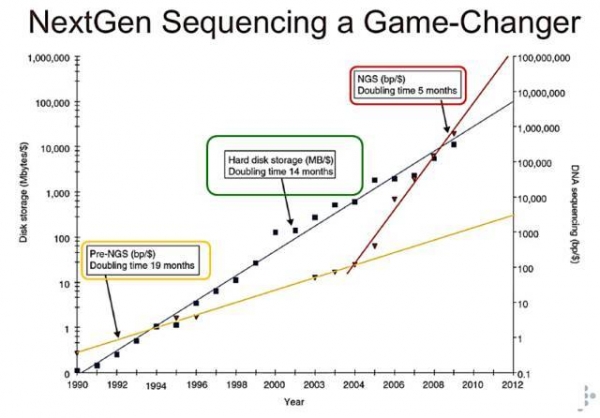
可以看出,现在用于存储的硬盘容量每14个月会有一倍的增长,而基因序列的数据量则每5月左右会翻一番,例如:CeleraGenomics 和Sanger Centre等主要基因研究机构都在管理数以万亿字节计的数据,其数据库信息量已经超过美国国会图书馆全部藏书,也超过了人类开展生物学研究以来积累的数据量。
序列拼接:序列拼接是将测序生成的reads短片段拼接起来,恢复出原始的序列。
该问题是序列分析的最基本任务,也是基因组研究成功与失败的关键,拼接结果直接影响到序列标注,基因预测、基因组比较等后续任务。基因组序列的拼接也是基因组研究必须解决的首要难题。其困难不仅来自它的海量数据(以人类基因组序列为例,从数量为10兆级的片断恢复出长度为亿级的原始序列),而且源于它含有高度重复的序列。
从计算机方面来讲,在拼接初期,会有大量的初始数据导入内存,然后对这些数据进行处理,因此,序列拼接对于计算机的内存量和计算能力都有非常大的需求。
基于结构的药物设计:人类基因工程的目的之一是要了解人体内约10万种蛋白质的结构、功能、相互作用以及与各种人类疾病之间的关系,寻求各种治疗和预防方法,包括药物治疗。
基于生物大分子结构及小分子结构的药物设计是生物信息学中的极为重要的研究领域。为了抑制某些酶或蛋白质的活性,在已知其蛋白质3级结构的基础上,可以利用分子对齐算法,在计算机上设计抑制剂分子,作为候选药物。然后在数据库中进行对比并且得到优势结构,最后使用分子模拟的方法实现药物分子的设计。
在通常的处理过程中,常用到如下软件:
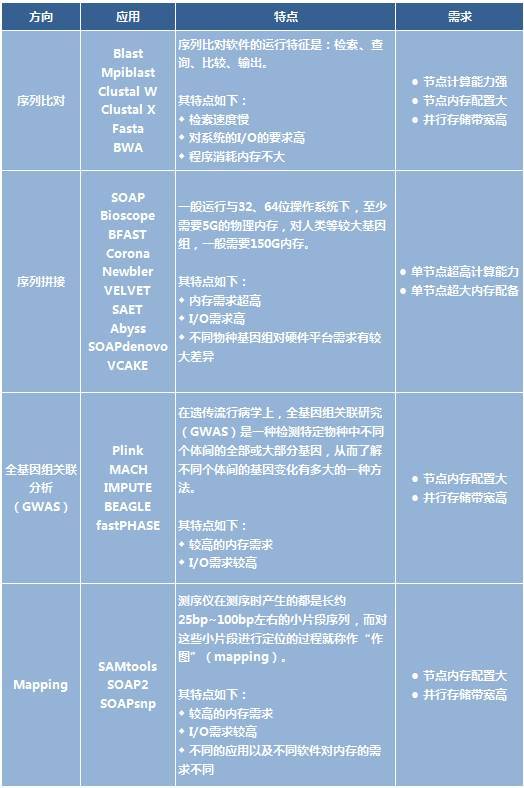
戴尔助力精准医疗展开“天使之翼”
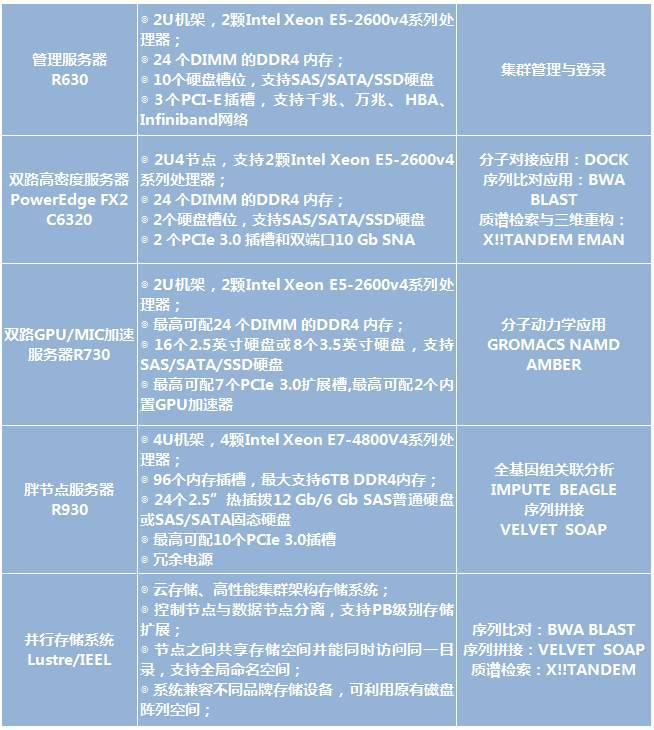
根据以上基因测序软件的普遍特点,戴尔高性能计算集群有如下配置建议:
基因比对、拼接等计算非浮点密集型计算应用,CPU利用率、idle%呈现规律性交替变化,并且程序起始阶段CPU利用率低,主要进行IO处理、高主频可加快进度,双路节点配置建议Intel E5-2660V4以上;
内存带宽随CPU利用率交替变化并且峰值并不高,内存容量需求较大,基本上是输入序列大小的5-6倍,单节点搭配8条16GB或32GB内存即可满足中小规模算例需求;对于大规模的基因拼接、比对计算,内存容量建议配置在1-2TB以上,DELL R930服务器最大可支持6TB内存(单根64GB*96根),可充分保障计算需求;
网络压力较低,仅在读写IO时涉及到较多网络传输,普通以太万兆即可满足网络带宽需求,选择IB网络或Intel OPA网络也会在一定程度上降低延迟、提升效率;
存储读写压力适中,磁盘读写均呈现阶段性,中小规模算例存储读写峰值带宽均在500MB/s以下,选用存储服务器DELL R730XD即可满足需求;大规模算例如人体全基因组比对、拼接等,在程序初始阶段输入文件磁盘读取、计算结果磁盘写阶段对存储的带宽压力会比较大,此时建议选择并行文件存储系统,比如IEEL,可提供GB/s以上的带宽,更好的应对存储压力。
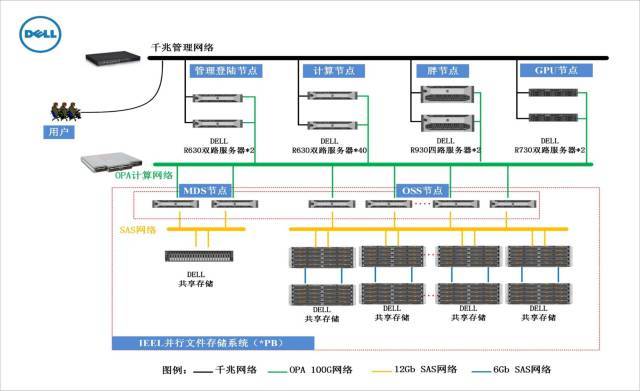
解决方案配置及拓扑示例
未来,在高性能计算支持下的精准医疗将飞速发展,并重塑医疗健康行业。戴尔高性能计算解决方案,将助力精准医疗展开“天使之翼”,不仅护卫患者生命安全,更守护每个人的健康,从此一马平川
好文章,需要你的鼓励


AI时代Chiplet设计中不可或缺的可观测性层
在基于Chiplet的架构中,可观测性正成为系统设计的关键缺失环节。多位半导体行业专家指出,AI可从硅层遥测数据中挖掘价值,但前提是架构须提供一致的检测手段、近传感器数据压缩及可编程采集能力。专家们强调,多供应商Chiplet生态系统需要标准化、安全的遥测模式,以实现跨芯片、封装和互联域的故障定位,同时保护敏感运营数据。目前,AI在遥测分析阶段已展现出显著价值,但可观测性的扩展本质上仍是架构问题。

当望远镜遇上“翻译官“:加州大学河滨分校等机构揭秘AI如何“读懂“星系照片
这项研究系统比较了四种AI图像分词策略在640000张星系图像上的表现,发现重建质量与物理属性预测能力之间存在根本性解耦,为天文基础模型的分词器选择提供了实验依据。

从传统CRM迈向智能化客户互动的转型之路
生命科学企业在全渠道战略和AI平台上投入巨大,但成效往往不尽如人意。问题根源不在于技术本身,而在于组织架构、数据治理和工作方式未能同步演进。许多转型项目止步于试点阶段,原因是各部门数据孤立、职责不清。要实现从传统CRM向智能互动的真正转型,企业需优先建立统一的数据基础和跨团队协作机制,并将AI能力嵌入日常工作流程,而非将其视为独立模块。

阿里Qwen团队教机器人“举一反三“:当AI大模型遇上机械臂,泛化能力的秘密在哪里?
阿里Qwen团队研究如何将大模型的规模化训练思路迁移到机器人操作领域,通过统一多机器人表示与38100小时数据预训练,让机器人在陌生场景和陌生机型上也能完成复杂操作任务。
2017
11/20
13:57
分享
点赞

从传统CRM迈向智能化客户互动的转型之路
Wonder与Zipline合作,无人机送餐服务将于2027年在德克萨斯州上线
无人机卫星通信突破:轻量化终端助力野火响应
Google承认AI发展速度已超过电网脱碳速度
欧盟拟将AWS和Azure列为数字市场"守门人"
隆湫资本完成对「蓝芯算力」Pre-B轮超3亿元独家投资
Visa、Stripe等140余家机构联合推出Open USD稳定币,剑指Tether
Anthropic发布Claude Sonnet 5大语言模型,编程能力与安全性双升级
Wayve以85亿美元估值启动8500万美元员工股权流动计划
遗留系统与数据缺口制约香港企业财资中心发展
美国要求OpenAI限制其最强大AI模型的访问权限
两党州长达成共识:数据中心建设费用不应转嫁给普通用户
