
AMD和英特尔联手了?!
相信大家这几天都被一则新闻刷屏——AMD和英特尔联手向英伟达发起挑战!乍看这则新闻令人匪夷所思,毕竟在接近半个世纪的时间里,AMD和Intel这对“冤家”上演了多场科技行业的经典对决!而分析人士指出,双方的合作倒也在情理之中,因为三者未来的竞争,已不在PC领域,而在这个正在来到我们身边的——AI的最好时代。”

伴随信息技术的发展,传统产业与信息化相结合,催生出智能制造、智能交通、智能物流、智能家居、智能家庭服务机器人、智慧健康养老等一批新业态新模式。“智能产业”的出现,为人工智能的发展提供了广阔的行业应用空间,极大促进了人工智能产业化进程。
在今年3月5日两会上发布的2017年政府工作报告中,明确指出要加快培育壮大包括人工智能在内的新兴产业,“人工智能”首次被写入了政府工作报告。
而此前,2016年国务院印发《“十三五”国家科技创新规划》,提出“面向2030年,再选择一批体现国家战略意图的重大科技项目”。经过千余名专家多轮论证,最终形成15个项目立项建议,中国科技部副部长阴和俊表示,结合当前人工智能迅速发展的态势,计划在已有的15个项目的基础上新增“人工智能2.0”,目前已进入实施方案的最终论证阶段。
人工智能在中国的政治、经济、学术领域都成为重中之重。这是中国 AI人最好的时代——2017年,中国人工智能迎来真正的新纪元。
激发“深度学习”潜能
人工智能发展是计算机硬件、软件技术演进的产物,其技术要素主要包括四个方面:
智能的传感系统,包括各类用于信息数据采集和环境感知的传感器件和设备;
智能的指挥中枢,主要指用于代替人脑的处理器芯片;
智能的信息处理算法,包括一切用于辅助人脑或模拟人脑进行认知学习、思维分析的软件算法;
海量的学习数据,为人工智能机器学习提供充足的先验样本。
互联网、移动互联网的蓬勃发展积累了海量的学习样本,深度学习算法的提出从软件层面模仿了人类大脑对底层信号的分级处理和特征提取,使得学习目标更精准、更有效,一批应用于语音和图像识别、机器翻译、机器搜索等领域的神经网络软件产品纷纷涌现。
然而,现有的神经网络分布式算法几乎全部建立在传统的集中式计算硬件架构基础上,在计算效率、能耗开销等方面存在严重的软硬件不匹配,无法从根本上发挥人工智能技术的优势,迫切需要从底层硬件层面加以解决,人工智能产业链重心开始向底层硬件迁移。
人工智能主要技术实现——深度学习,实质是通过构建具有很多隐层的机器学习模型和海量的训练数据,来学习更有用的特征,从而最终提升分类或预测的准确性;抽象层面越高,越有利于分类。
大数据+深度学习:颠覆传统行业计算与分析方式
深度学习架构概览
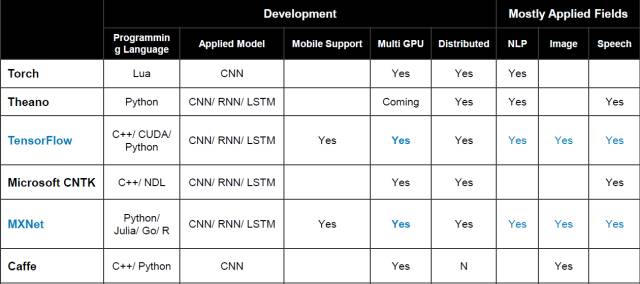
深度学习的建议配置
训练阶段(For training use),clusters of 8-32GPUs
-
Best perf, perf/W, perf/$, and memory bandwidth
-
Training of DL has forwarding (inference) and backward calculation flow with high frequent data exchange between layers
-
Need inter-GPU bandwidth –Nvidia support up to 8 direct GPGPU memory mapping
-
Benefits from Higher CPU/Memory frequency
-
Need performance storage for some cases, e.g. ImageNet
-
Need local storage capacity
-
GPU RDMA direct required and MPI compliant preferred
-
“Less intra-node traffic, More in-chassis traffic” could improve computation efficient by task (8xGPGPU in one chassis get largest interest today)
-
HPC compliant with certain PCIe Switch topology design
预测阶段(For inference),数据中心使用CPU或单个GPU, e.g. Tesla M4/P4 and M40/P40。
在移动设备上的预测阶段(For inference in mobile devices,如车联网,或物联网), 使用CPU或mobile TX1 。
获取最佳性能及效率(For the absolute best performance and efficiency),使用ASIC
-
确认设备相符(memory limited ASICs no better than GPU)
-
确认运算法则不会发生改变(your algorithm isn’t going to change)
最多节省几周时间!得GPU者得AI
CPU在一次计算一条指令(单指令单数据)方面表现出色,该指令在少量数据上运行。这涵盖绝大多数应用程序。但是,当处理大量数据或者需要最快的处理时,其他技术就会发挥作用。
GPU提供单指令多数据计算。一个指令可以一次处理大量的数据。例如,将两个数字向量相加。这是非常有效的,但是很难编程,并且许多问题不能映射到这个模型中。
Dell PowerEdge C4130 GPU优化型服务器可在专为高性能计算(HPC) 工作负载和虚拟桌面基础架构(VDI) 而设计的超高密度平台中提供超级计算敏捷性和性能。在不影响多功能性或数据中心空间的情况下,加速处理医药、金融、能源勘探及相关领域中最复杂的研究、仿真和虚拟化问题。

PowerEdge C4130外观与内部结构设计
NVIDIA是当前深度学习/AI领域最火的硬件厂商,P100是其最强大的GPU。Dell PowerEdge C4130支持四块P100,在深度学习领域是非常先进的计算/加速平台。
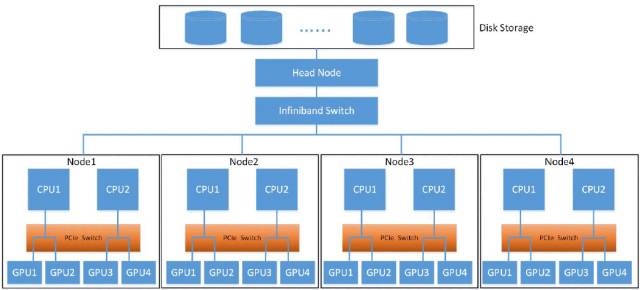
P100的深度学习集群配置:

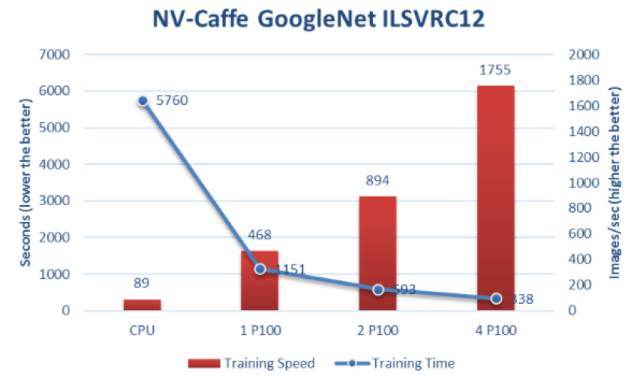
使用P100 GPU在NV-Caffe中的
GoogleNet的培训速度和时间
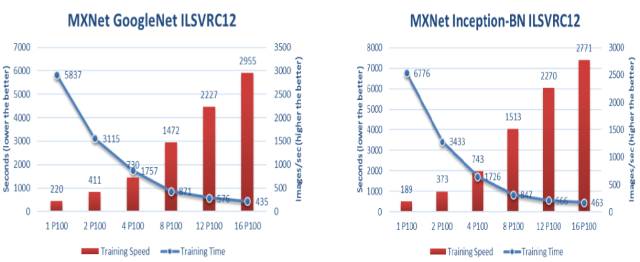
使用P100 GPU在MXNet中的培训速度和时间
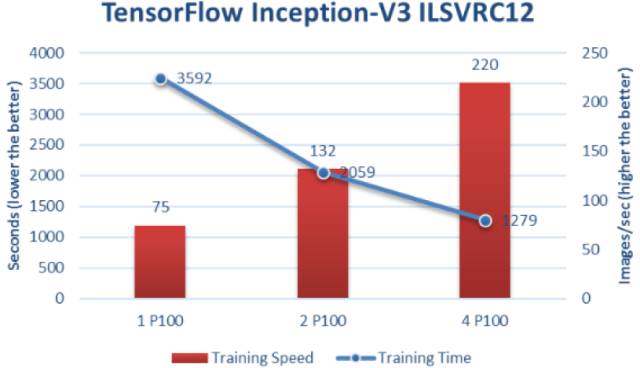
使用P100 GPU的TensorFlow中
Inception-V3的训练速度和时间
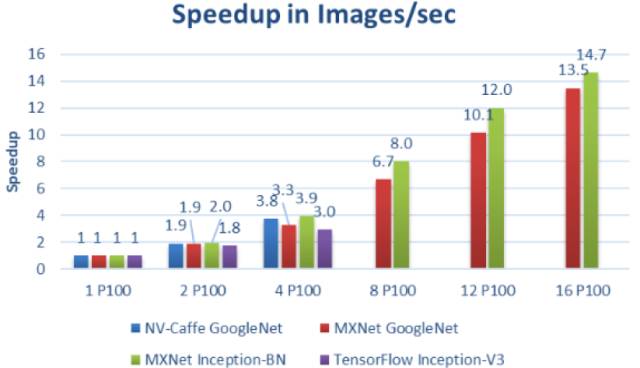
不同Deep Learning框架
和网络中多个P100 GPU的加速
在Dell PowerEdge C4130服务器中使用多个P100 GPU并使用多个服务器节点时,可以看到神经网络训练的极大的加速和可扩展性。随着P100 GPU数量的增加,训练速度增加,训练时间减少。
从显示的结果看,很明显,戴尔的PowerEdge C4130集群是一个强大的工具,大大加快神经网络训练。
在实践中,真实的用户应用程序可能需要几天或几周的训练模型。例如,真实应用的训练可能需要120个图像的90个时期。带有P100 GPU的戴尔C4130可以在不到一天的时间内打开结果,而CPU耗时大于1周 ——显而易见,这对最终用户是真正的好处。
实际使用情况的效果是每次运行节省几周的时间,而不是几秒。

PowerEdge C4130 GPU支持
Dell PowerEdge C4130服务器支持NVLink技术,NVLink是一种高带宽且节能的互联技术,能够在CPU-GPU 和GPU-GPU 之间实现超高速的数据传输。
NVLink技术的数据传输速度是传统PCIe3.0速度的5到12倍,能够大幅提升应用程序的处理速度。

PowerEdge C4130支持NVlink(chassis K)
深度学习的训练(training)阶段很花时间,Dell PowerEdgeC4130服务器+P100的配置能够充分满足其对于硬件的要求;而针对深度学习的inferrence阶段,建议采用Dell PowerEdgeR730服务器+Nvidia P4加速平台来搭建,确保获得优异性能的同时,实现功耗低、成本低。
好文章,需要你的鼓励


Glean年收入突破3亿美元,削减AI成本成核心卖点
企业AI搜索公司Glean宣布年度经常性收入(ARR)达3亿美元,较15个月前的1亿美元增长三倍。尽管谷歌、微软、OpenAI等科技巨头纷纷入局企业AI搜索市场,Glean凭借"上下文图谱"技术深度理解企业业务需求,并帮助客户显著降低AI计算成本。该公司提供按用量计费和混合定价两种模式,客户涵盖Databricks、Reddit、Pinterest及三星等企业。Glean上轮融资后估值达72亿美元。

香港中文大学与MiniMax联手破解AI图像描述的“说多错多、说少漏多“困局
香港中文大学与MiniMax提出ClaimDiff-RL框架,将图像描述的AI训练从整体打分升级为逐条核查,有效解决了传统方式导致AI"少说保平安"的问题,同时在多项基准测试上超越Gemini-3-Pro-Preview。

蓝色起源“新格伦“火箭在佛罗里达测试中发生爆炸
杰夫·贝索斯旗下的蓝色起源公司在佛罗里达卡纳维拉尔角进行静态点火测试时,新格伦重型火箭发生爆炸。这是美国历史上最大规模的火箭爆炸之一,也是蓝色起源公司遭遇的最严重失败。所有人员安全,但该事故可能导致新格伦火箭项目长期暂停。此前该火箭已成功完成三次发射,并实现了助推器回收和重复使用。

NTU、HKU等多所顶校联手,让AI同时“多角度看片“——视频理解的并行探针革命
ParaVT是一个由南洋理工等多校联合提出的并行视频工具调用框架,通过让AI同时分析多段视频并引入PARA-GRPO算法解决训练中的格式崩溃与工具跳过问题,在六项长视频理解测试中平均提升约7.9%。
2017
11/20
14:50
分享
点赞

Glean年收入突破3亿美元,削减AI成本成核心卖点
蓝色起源"新格伦"火箭在佛罗里达测试中发生爆炸
智能体AI正在重塑企业架构与Token经济学
堪培拉理工学院如何借助技术革新重塑课堂教学体验
Gemma 4携手Arm:优化端侧AI,加速移动应用体验
制药公司与初创企业如何携手推动AI落地
《星球大战》导演盛赞生成式AI:电影制作的革命性工具
Salesforce借助Informatica布局企业级无头数据管理架构
几乎所有M5 MacBook Air配置现在都降价近200美元
企业用好Agent,关键不在“买一个智能体”|原点Talk 分享会
大模型评测风向变了,Testin云测如何构建企业级AI质量标尺?
因民事养老金管理失误,英国政府拒绝向Capita授予5.63亿英镑合同
