
从智人到智神,你跟的上吗?
“人类会沦为喂养大数据智能的人肉饲料?机器的智能越来越比人更适合工作?机器对人类的理解,可能超过我们对自己的理解?各种想不清楚?然而,未来已经来了!生命本身就是数据处理,算法将战胜自由意志…这一次,进步来得太快,企业想要跻身前列,确实需要具备“诸葛”智慧。”
你或许没看过冯小刚的 《天下无贼》,但应该听过这句经典的台词:“21世纪什么最重要?人才!”电影拍完这么多年,明星红了一轮又一轮,这句话却仍被人津津乐道。究其原因,可以说是人类作为这个世界统治者对于自身智慧的一种自信和骄傲。所以,人的智慧不会被打败?然而,啪啪打脸的事情接连发生……2017人机大战三番棋第三局结束,柯洁执白209手中盘负于AlphaGo,人机大战2.0的结局被定格在了0:3,意味着以AlphaGo为代表的人工智能,完胜以柯洁为代表的人类顶级围棋选手。
AlphaGo是当下炙手可热人工智能的产物,充足的数据和半自主学习让它能不断训练优化,战胜最顶尖的人类职业围棋手。
那么究竟什么是人工智能?
该领域经历了怎样的发展?
国际巨头如何布局?
未来又将走向何方呢?
人工智能:时间轴上的奔跑
人工智能是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学,可以分为计算智能、感知智能、认知智能三个进阶。现在公认的人工智能起源是1956年的达特矛斯会议。在会议上,计算机科学家John McCarthy说服了参会者接受“人工智能(Artificial Intelligence)”这一概念。达特矛斯会议之后的十几年是人工智能的第一次黄金时代,但由于计算机性能的瓶颈、计算复杂性的增长以及数据量的不足,人工智能进入了低谷期。1970年之后,人工智能找到新的思路:不光要研究解法,还得引入知识,机器学习成为人工智能的焦点,其目的是让机器具备自动学习的能力,通过算法使得机器从大量历史数据中学习规律并对新的样本作出判断识别或预测。1996年深蓝(基于穷举搜索树)战胜了国际象棋世界冠军卡斯帕罗夫,成为机器学习的里程碑的一步。

深度学习是机器学习的第二次浪潮。2006年Geoffrey Hinton提出深度学习概念,同年Yann LeCun发表了Deep Learning模型——卷积神经网CNN(Convolutional Neural Networks),人工智能获得突破性进展。深度学习通过大量的数据分析用户需求,匹配其需要的信息,当前很多购物平台与推荐类APP即是如此。另外像自动驾驶、实时语音翻译、自动回复电子邮件、脸部识别等都是深度学习的研究范畴。
CNN的原理是模仿人类神经元的兴奋构造:大脑中的一些个体神经细胞只有在特定方向的边缘存在时才能做出反应,现在流行的特征提取方法就是CNN。打个比方,当我们把脸非常靠近一张鸽子的图片观察的时候(假设可以非常非常的近),这时候只有一部分的神经元是被激活的,我们也只能看到鸽子的图片上的像素级别点。当我们把距离一点点拉开,其他部分的神经元将会被激活,我们也就可以观察到鸽子的羽毛线条→图案→局部→整个鸽子,整个就是一步步获得高层特征的过程。
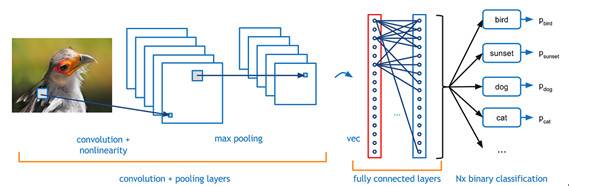
人工智能:生态系统的自我搭建
人工智能的生态链分为三层:基础层、技术层和应用层。基础层最核心的是数据资源和计算能力,如各类芯片、存储设备、传感器、数据及云平台资源等;技术层是算法、模型和应用开发,如计算智能算法、感知智能算法、认知智能算法;应用层是硬件产品与各行业的软件应用,如智能机器人、虚拟客服等。
人工智能按阶段可以分为计算智能、感知智能、认知智能三个进阶。计算智能是最初级阶段,主要是计算能力的进化、算法的优化和硬件(CPU芯片)的技术进步;感知智能有赖于数据获取技术,目前主要有语音识别和机器视觉两种技术;认知智能是最高级的形态,也是未来需要突破的方向,目前尚处在感知智能的阶段。
过去5年人工智能最大的技术突破是Deep Learning中的无监督学习技术。未来5~10年,深度学习将向更多行业渗透,特别是数据密集型行业。大数据 + 深度学习 = 智能 + (服务、制造、……)。
人工智能:辐射全球,大势所趋
百度将NLP(自然语言处理)、KG(知识图谱)、IDL(深度学习研究院)、Speech(语音)、Big Data(大数据)等在内的核心技术深度整合,组成百度AI技术平台体系(AIG),李彦宏将百度定位于一家人工智能公司;人工智能是阿里巴巴在科技领域的核心关注技术,并且在云端拥有包括语音识别、OCR、智能交通、聊天机器人、人脸识别及个性化推荐在内的各项领先产品及技术,阿里巴巴的城市大脑已在杭州落地,构建智能之物是阿里AI的目标;腾讯成立AI Lab,专注于人工智能的基础研究,主要包括计算机视觉、语音识别、自然语言处理和机器学习这四个垂直领域,将在内容、社交、游戏和平台工具型AI四个方向进行研发与应用合作。
Google公司新的模拟神经网络算法,拥有更强大的逻辑处理能力;其自动驾驶汽车已完成总计70万英里的高速公路无人驾驶巡航里程;未来谷歌图片识别引擎不仅能识别出照片的对象,而且能对场景进行简单准确的描述;在语音识别方面,新开发了整合公司海量数据的语音系统,使计算机能听懂和思考人们向谷歌设备输入的语音。
微软公司深度学习系统识别2012年版的ImageNet图像数据库错误率只有4.94%,低于普通人的5.1%,其CPU由微软的Azure云服务提供支持;而其隐形用户界面技术可以让用户在触摸或发出语音指令之前,设备就能“明白”他们的意图。
戴尔:让企业人工智能落地
戴尔黄陈宏博士认为,数据和计算能力是人工智能的基础,人工智能只有在云计算的支持下,有成熟的技术平台,将应用、分析、数据深度结合起来才有生命力。这也是戴尔长期的实践和做法:从企业级的技术和平台着手,以应用驱动来破人工智能这个局,继而让人工智能商业化。

戴尔全球副总裁、大中华区总裁黄陈宏博士
对于企业来说,真正的将人工智能用起来,才可以体现人工智能的价值,戴尔的做法就从人工智能商业化面临的挑战入手。
首先,优化IT基础架构。戴尔利用高性能计算平台,真正的优化成本,让人工智能的平台成本下降到了三分之一。
第二,在应用中解决人才的问题。面对中小企业如何培养人工智能团队的难题,戴尔的“诸葛·深知”平台,可以作为企业的共有平台。每个行业根据自己的要求和理解,利用“诸葛·深知”的深度学习算法解决难题。
第三,落地人工智能的平台,要从数字化转型着手。企业要尽早规划赶上潮流,让智能化数字化成为重要组成部分。
秉承这三点原则,针对人工智能在中国的普及化及应用的加速落地,戴尔和中科院自动化所共同构建“企业级深度学习应用与服务平台——诸葛·深知”。平台致力于为企业级客户提供包含硬件、软件和专业服务的一站式AI解决方案,通过深度学习专业知识进行图像识别、语音识别、自然语言处理,以及行业AI应用的数据评估和模型开发,帮助中国企业更快实现人工智能落地。
“易于使用,调度优化”,是“诸葛·深知”平台的特色。针对AI市场上各种各样的深度学习框架和工具集,各类复杂的算法,“诸葛·深知”平台为企业用户提供深度学习工具包的统一接口,众多中科院的成熟算法模型可以轻松调用。搭建Dell提供的算法优化的高性能计算平台,提供持续性能和可用性保证。
“小诸葛”深度学习IT平台解决方案
为更好的优化人工智能的计算平台,戴尔在与中科院自动化所启动“企业级深度学习应用与服务平台——诸葛·深知”后推出了“小诸葛”深度学习IT平台解决方案,通过此方案可支持企业、科研院校及政府、电商等领域的人工智能应用与研究,由戴尔的高性能计算集群、并行存储系统、高速网络互连方案组成,提供端到端深度学习基础架构平台交付。
深度学习基础架构技术要求:
超强的浮点计算性能,支持多GPU/Xeon Phi;
高速低延迟的集群交换网络;
大容量的文件存储系统,并行或者分布式技术满足存储性能要求;
集群硬件资源的统一调度与管理;
多种机器学习工具集、函数库支持。
“小诸葛”的重要组成
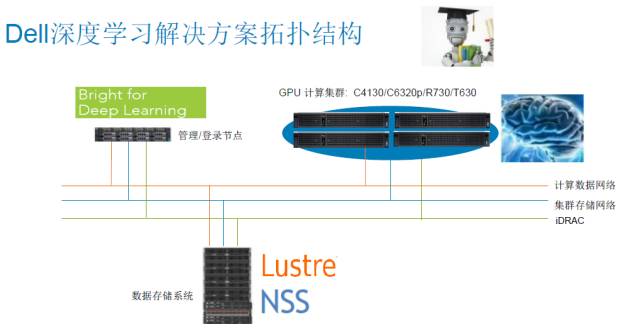
CPU+GPU集群工作模式
利用CPU+GPU集群工作模式,为用户提供高速数据处理。
高速InfiniBand网络互连
处理器之间或计算节点之间的快速互联网络的重要程度并不亚于处理器本身,戴尔可根据需要提供Infiniband、OmiPath、100Gb/40Gb/25Gb/10Gb以太网等多种高速网络互联方案。
并行可扩展文件系统
提供并行可扩展文件系统,解决深度学习平台的容量和性能挑战。
领先的BCM集群任务管理
采用高性能、高可靠性设计的集群管理软件,支持常用深度学习框架、工具集、函数库与硬件驱动。
优质的支撑服务
提供优质的服务来支撑深度学习基础架构平台顺利交付。
“小诸葛”之主要引擎:GPU计算集群
人工智能的春天到来,其重要因素之一是GPU处理能力,能让神经网络的智能可以随数据增加而继续提升,突破了过去的人工智能所能达到的平台,训练饱和极限(智力容量)大大上移。深度学习需要较高的计算能力,所以对GPU的选择会极大地影响使用者体验。在GPU出现之前,一个实验可能需要等几个月,或者跑了一天才发现某个试验的参数不好,好的GPU可以在深度学习网络上快速迭代,几天跑完几个月的试验,或者几小时代替几天,几分钟代替几小时。
用于深度学习的GPU的高速取决于什么? 是CUDA核? 时钟速度?TFLOPS值?还是RAM大小?这些都不是,影响深度学习性能的最重要的因素是显存带宽。由于冯诺依曼体系架构计算与存储分离的特性,导致大量时间耗费在CPU和GPU(采用PCIe),GPU和GPU(采用NVlink),GPU中计算部件和显存之间的数据倒腾,单块GPU的带宽主要指的就是内存带宽。
戴尔用于深度学习的高性能利器--PowerEdge C4130通过在每个C4130服务器中结合使用最多2个IntelXeon. E5-2600 v4处理器和4个300W 双宽度GPU,更快地获得更精准的结果。支持NVIDIAGPU和多达1TB的DDR4内存,在服务器架构与特定性能需求相配合方面得心应手。

此外,戴尔还推出了基于英特尔XeonPhi(融核)处理器的高性能服务器节点PowerEdge C6320p,至强Phi(融核)处理器英特尔完全针对HPC设计的CPU ,其能力就是最大限度的解决高性能计算系统瓶颈问题,同时至强融核CPU核内集成了高带宽的内存,这个内存不是通常的内存条,而是在CPU里面会集成16GB快速内存,最后集成英特尔的Omni-Path,100GB的高速互连网络,非常适合人工智能、机器学习等应用平台。
戴尔PowerEdge C6320p设计成半宽1U的服务器节点,一个C6320p机箱中至多可容纳4个节点,它可在一个2U空间中提供288个无序内核。每一个至强融核处理器至多72个无序内核,并提供低延迟I/O选项(英特尔Omni-Path或Mellanox EDR InfiniBand架构),它还可以为并行代码提供更佳的性能。通过每周期能够执行32位双精度浮点运算特点,PowerEdge C6320p在高度矢量化和并行的高性能计算应用的性能表现可以提升两倍。
相比NVIDIA GPU在深度学习training阶段的领跑,C6320p更兼顾传统HPC应用,适用面更广。适合没有CUDA编程能力,同时对并行性要求较高的应用。
下面是戴尔在HPC计算节点的应用场景的一个简约对比说明,提供了高效稳定,丰富多样的深度学习平台。

戴尔“小诸葛”深度学习IT平台解决方案具有如下优势:
Dell提供GPU计算、CPU计算、胖节点等多种计算平台,满足深度学习浮点计算强度;
Dell C4130 1U空间内支持4块NVIDIA目前性能最强的P100 GPU(即将支持V100)且支持NVLink版本;
Dell C6320P2U空间内支持4节点IntelXeon Phi并行计算平台,可兼顾传统HPC应用;
Dell提供并行存储系统,满足PB级文件存储的容量和性能要求;
Dell提供Infiniband、OmiPath、100Gb/40Gb/25Gb/10Gb等丰富多样的高速网络互联方案;
Dell提供集群管理软件支持HPC集群调度与管理,支持业界常用AI深度学习框架、工具集、函数库与硬件驱动;
Dell服务团队提供端到端深度学习基础架构平台交付。
自深度学习被Hinton在《Science》发表以来,短短的不到10年时间里,带来了在视觉、语音等领域革命性的进步,引爆了这次人工智能的热潮。虽然目前仍然存在很多差强人意的地方,距离强人工智能还是有很大距离,但它是目前最接近人类大脑运作原理的算法,相信在将来,随着算法的完善以及数据的积累,甚至硬件层面仿人类大脑神经元材料的出现,深度学习将会更进一步的让机器智能化。戴尔会秉承人工智能“技术商业化”理念,持续优化“小诸葛”深度学习IT平台解决方案来支撑人工智能的应用,支持企业数字化转型落地。
来源:至顶网云计算频道
好文章,需要你的鼓励


AI时代Chiplet设计中不可或缺的可观测性层
在基于Chiplet的架构中,可观测性正成为系统设计的关键缺失环节。多位半导体行业专家指出,AI可从硅层遥测数据中挖掘价值,但前提是架构须提供一致的检测手段、近传感器数据压缩及可编程采集能力。专家们强调,多供应商Chiplet生态系统需要标准化、安全的遥测模式,以实现跨芯片、封装和互联域的故障定位,同时保护敏感运营数据。目前,AI在遥测分析阶段已展现出显著价值,但可观测性的扩展本质上仍是架构问题。

当望远镜遇上“翻译官“:加州大学河滨分校等机构揭秘AI如何“读懂“星系照片
这项研究系统比较了四种AI图像分词策略在640000张星系图像上的表现,发现重建质量与物理属性预测能力之间存在根本性解耦,为天文基础模型的分词器选择提供了实验依据。

从传统CRM迈向智能化客户互动的转型之路
生命科学企业在全渠道战略和AI平台上投入巨大,但成效往往不尽如人意。问题根源不在于技术本身,而在于组织架构、数据治理和工作方式未能同步演进。许多转型项目止步于试点阶段,原因是各部门数据孤立、职责不清。要实现从传统CRM向智能互动的真正转型,企业需优先建立统一的数据基础和跨团队协作机制,并将AI能力嵌入日常工作流程,而非将其视为独立模块。

阿里Qwen团队教机器人“举一反三“:当AI大模型遇上机械臂,泛化能力的秘密在哪里?
阿里Qwen团队研究如何将大模型的规模化训练思路迁移到机器人操作领域,通过统一多机器人表示与38100小时数据预训练,让机器人在陌生场景和陌生机型上也能完成复杂操作任务。
2017
12/11
11:07
分享
点赞

从传统CRM迈向智能化客户互动的转型之路
Wonder与Zipline合作,无人机送餐服务将于2027年在德克萨斯州上线
无人机卫星通信突破:轻量化终端助力野火响应
Google承认AI发展速度已超过电网脱碳速度
欧盟拟将AWS和Azure列为数字市场"守门人"
隆湫资本完成对「蓝芯算力」Pre-B轮超3亿元独家投资
Visa、Stripe等140余家机构联合推出Open USD稳定币,剑指Tether
Anthropic发布Claude Sonnet 5大语言模型,编程能力与安全性双升级
Wayve以85亿美元估值启动8500万美元员工股权流动计划
遗留系统与数据缺口制约香港企业财资中心发展
美国要求OpenAI限制其最强大AI模型的访问权限
两党州长达成共识:数据中心建设费用不应转嫁给普通用户
