
重磅!华云数据“信创云基座”入围工业和信息化部网络安全产业发展中心2020年信息技术应用创新解决方案典型案例
2021年4月28日,华云数据“信创云基座”凭借突出的技术水平成功入围工业和信息化部网络安全产业发展中心发布的“2020年信息技术应用创新解决方案典型案例”名单。
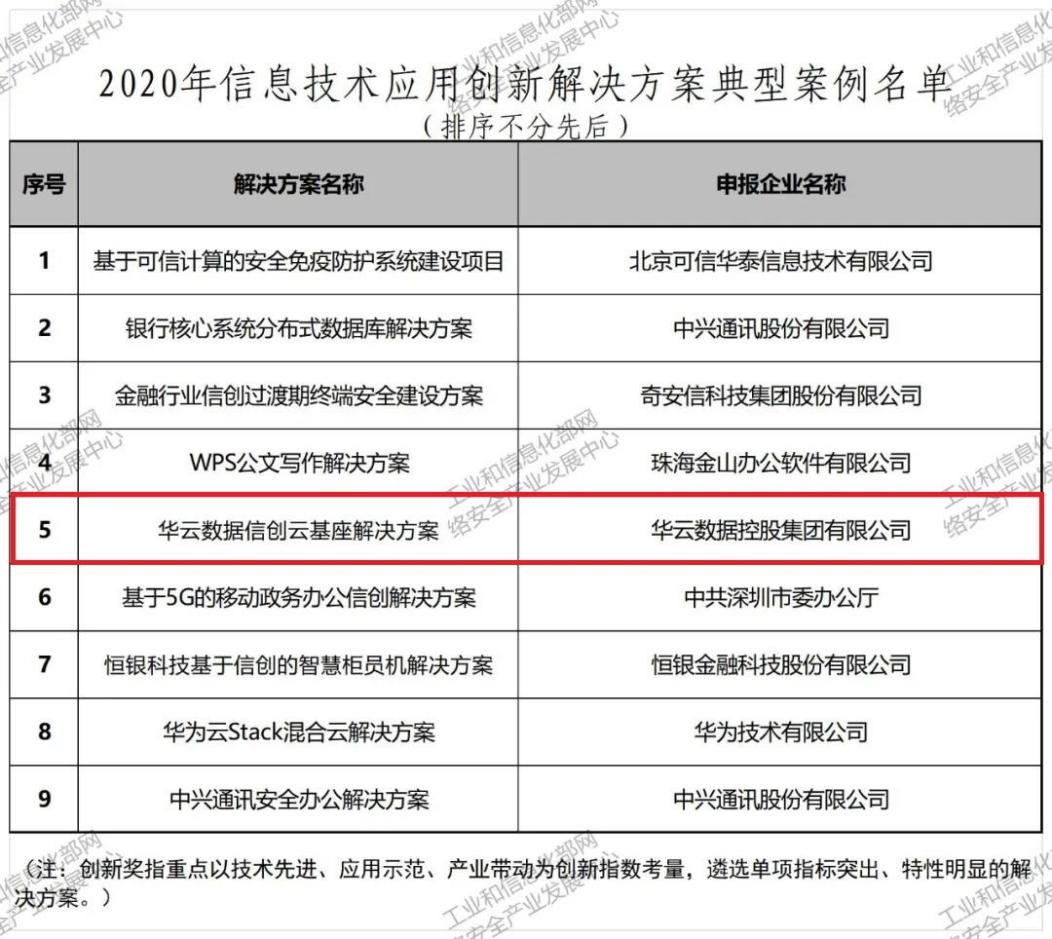

本次入围的名单经过材料征集、形式审查、技术初评、专家评审答辩等四个严苛环节筛选后得出,入围的典型案例将纳入信息技术应用创新案例库,旨在进一步促进信息技术应用创新供需协同的持续提升,及时让广大用户了解掌握信息技术应用创新最新成果。
信创是实现国家十四五规划发展目标的重要抓手。在多方利好政策的支持下,我国信创产业的创新能力将得到进一步提升。形成以企业为主体、市场为导向、产学研用深度融合的技术创新体系,为我国数字化社会发展奠定坚实基础。
华云数据是信创云计算专家,此次入围的“信创云基座”是华云数据围绕信创发展要求和用户需求,基于其在云计算领域的自主创新与深厚积累,推出的一套面向信创云的完整的软件定义基础架构平台。
“信创云基座”以国产通用型云操作系统安超OS为技术基础,兼容不同x86、ARM、自主创新芯片的硬件平台与操作系统;借助异构环境统一纳管能力实现信创云平台与底层硬件解耦;结合可信计算、资源隔离、数据加密等安全机制保障信创云平台安全可用;通过自助式运维服务满足信创云平台高效管理;采用华云数据信创基地群的生态适配工序,为用户提供可信赖的信创业务解决方案。
在华云数据的信创全面布局下,“信创云基座”具备信创适配软实力与信创部署硬实力。信创适配软实力体现在广泛生态适配能力、业务适配优化能力和混合IT架构支持能力;信创环境硬实力体现在华云数据位于安徽和江苏两省的信创攻关基地。依托于信创基地,华云数据能够打造信创云建设与交付的闭环,从信创云的项目评估调研开始,到产品与方案的适配与选型、项目的集成与培训、一直到项目交付和运维服务,华云数据能够提供信创云全生命周期的服务,提供一站式的信创云建设与交付方案。
华云数据利用“信创云基座”不仅解决了我国核心技术“卡脖子”的问题,驱动用户新旧动能转化,加快数字化转型进程,还带动了信创生态的繁荣,壮大国产化产业规模,推动信创产业纵深发展。
对于华云数据来说,此次“信创云基座”能够入围典型案例,是对其积极响应国家号召,坚定不移定地走科技创新战略,实现“信创强国”理想的一次有力肯定。而这次肯定也将内化为激励华云数据奋勇前行的动力。未来,华云数据将继续发挥自主创新的技术优势,持续提升创新能力和核心竞争力,同时,积极参与到信创产业生态共建的行动之中,坚持不懈地推动我国自主安全可控的信创生态良性发展,为持续构建科技强国再做贡献。
来源:业界供稿
好文章,需要你的鼓励



Adobe与UCLA联手突破AI模型速度瓶颈:让图像生成快一倍的“稀疏化魔法“
Adobe研究院与UCLA合作开发的Sparse-LaViDa技术通过创新的"稀疏表示"方法,成功将AI图像生成速度提升一倍。该技术巧妙地让AI只处理必要的图像区域,使用特殊"寄存器令牌"管理其余部分,在文本到图像生成、图像编辑和数学推理等任务中实现显著加速,同时完全保持了输出质量。

# 思科自研AI模型正式应用于产品,首先赋能身份安全服务
思科宣布其自主开发的AI模型已准备就绪,开始为公司产品提供支持。该模型名为"Foundation-Sec-1.1-8B-Instruct",是基于Meta Llama-3.1-8B架构的80亿参数指令调优模型,专门针对网络安全应用进行优化。首个应用场景是Duo身份智能服务,通过分析用户登录行为、地理位置和设备使用情况,识别传统访问控制容易遗漏的异常模式,并生成每周安全摘要报告,帮助管理员更好地进行安全决策。

不用再训练AI模型,香港科技大学团队发明“智能管家“,让AI一眼就知道该抓哪里用哪里
香港科技大学团队开发出A4-Agent智能系统,无需训练即可让AI理解物品的可操作性。该系统通过"想象-思考-定位"三步法模仿人类认知过程,在多个测试中超越了需要专门训练的传统方法。这项技术为智能机器人发展提供了新思路,使其能够像人类一样举一反三地处理未见过的新物品和任务。
2021
04/29
10:35
分享
点赞

# 思科自研AI模型正式应用于产品,首先赋能身份安全服务
超大规模云厂商在2025年是解决了电力问题还是重新思考了问题?
# 英伟达成为唯一能免费提供AI模型的厂商
Retell AI推出自动化质检系统,解决语音智能体人工审核瓶颈
# 法国生物科技公司发布全球首个生物学通用AI模型
# JEDEC开发减少引脚数的HBM4标准以提升容量
# Ewigbyte光学归档存储技术及战略解析
2025年:可穿戴设备全面转向AI技术
# Oracle领衔科技巨头5000亿美元AI数据中心租赁狂潮
新农人:西云数据如何绘制智慧农牧“全景图”
据说算力高达1000 TOPS,华硕Ascent GX10深度评测——开箱
苹果发现:只需一个注意力层,就能让AI图像生成既快又好
