
实力夺冠!天翼云在国际AI顶会大模型挑战赛中脱颖而出
6月7日,国际人工智能顶会CVPR 2023举办的第一届大模型挑战赛(CVPR 2023 Workshop on Foundation Model:1st foundation model challenge)落下帷幕,本次比赛吸引了来自全球著名高校和知名企业的1024名参赛者。经过为期2个月的激烈角逐,天翼云AI团队(队名CTRL)在多任务大模型赛道中表现出色,荣获本届大赛冠军。
CVPR会议是由IEEE主办的关于计算机视觉和模式识别的国际学术会议,收录了该领域最新的研究成果和技术发展,是全球计算机视觉三大顶级会议之一。
传统的视觉模型生产流程通常采用单任务,从零开始训练,各个任务之间无法相互借鉴。由于单任务数据有限,导致模型的实际效果过于依赖任务数据分布,通常对于不同场景的泛化效果不佳。
近年来,大数据预训练技术迅速发展,通过利用大量数据学习通用知识并将其迁移到下游任务中的方法,本质上实现了不同任务之间的相互借鉴。基于海量数据获得的预训练模型具有较好的知识完备性,即使在下游任务中使用少量数据进行微调,仍然能够获得良好的效果。然而,基于预训练+下游任务微调的模型生产流程需要为每个任务单独训练模型,这在研发上消耗了大量资源。相比之下,多任务训练方案通过使用多个任务的数据训练一个功能强大的通用模型,可以直接应用于处理多个任务,从而有效提高模型生产效率和泛化能力。
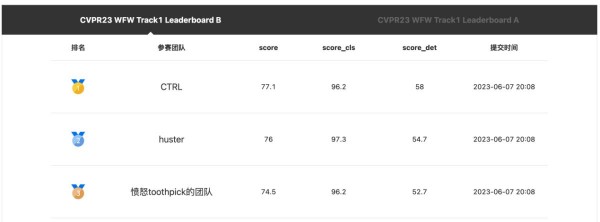
在本次竞赛中,参赛者需要使用单一模型同时完成交通场景下的分类、检测和分割三个代表性任务的联合训练。天翼云AI团队在模型设计方面凭借丰富的算法开发经验,选择了参数量仅为第2名60%的预训练模型,用更少的参数却获得了更高的精度。
为了解决多任务训练中各分支损失函数和梯度不一致导致收敛缓慢的问题,天翼云AI团队采用了损失均衡和梯度尺度统一的方法,以此来平衡各任务分支的损失函数,并使梯度具有一致的尺度,从而提高模型的训练效率和收敛速度。此外,天翼云AI团队还通过精心设计的任务专属特征金字塔和注意力机制,使各分支任务能够利用骨干网络中对自身任务更有效的特征,进一步提升了整体模型的精度和性能。
通过以上模型设计和训练策略,天翼云AI团队在竞赛中取得了优异成绩,充分展示了在图像、音频及多模态领域的深厚积累和持续创新能力。未来,天翼云将继续在广阔的人工智能领域进行创新和探索,以更先进的技术和卓越的成果惠及更多用户,为千行百业的数字化发展提供支撑。
来源:业界供稿
好文章,需要你的鼓励


iOS 26.5.2正式发布,包含逾20项安全修复,Claude协助发现漏洞
苹果于6月29日发布iOS 26.5.2,带来超过二十项安全修复,其中多项针对WebKit引擎的恶意网页内容漏洞。值得关注的是,Anthropic旗下Claude AI协助发现了其中一个潜在内存损坏漏洞。用户可前往"设置-通用-软件更新"立即下载安装。随着AI辅助安全研究的深入,Claude未来或将更频繁地出现在CVE漏洞报告中。

慧眼难辨“何时何处“——慕课里AI通才的专业盲区,庆应义塾大学新出的这套考卷让15个顶级模型集体翻车
庆应义塾大学与英伟达推出AnyGroundBench,测试15个顶级视觉语言模型在手术、工业等五大专业领域的时空定位能力,揭示当前AI在专业场景下的系统性空间定位瓶颈。

Visual Studio 2026 六月更新优化 GitHub Copilot 用量追踪
微软发布Visual Studio IDE 2026年六月更新,新增GitHub Copilot用量窗口,可实时显示用户在基于Token消耗计费模式下的使用情况。此次更新还引入了MCP服务器双重信任验证机制,在启动前后分别对配置和工具指纹进行比对。此外,C++现代化Agent正式发布,Next Edit建议范围扩展至整个活动文件,Emoji也在编辑器全局实现彩色渲染。

清华大学与蚂蚁集团联合打造“数据科学AI考官“:AgenticDataBench如何给数据智能体打出一张精准成绩单?
清华大学与蚂蚁集团联合推出AgenticDataBench,含344道真实数据科学任务和433个精细技能标签,系统评测12种主流数据智能体配置的能力边界与短板。
2023
06/12
17:06
分享
点赞

科学家研究证明:我们并非生活在模拟现实中
苹果与博通签署高达300亿美元芯片采购协议
零信任网络访问如何从根本上消除隐性信任
Crusoe扩展AI平台:推出无服务器微调与自助推理部署
Oratomic完成3亿美元融资,仅需2万个量子比特造出实用量子计算机
Anthropic将Claude Cowork智能体扩展至网页端与移动端
OpenAI发布延迟模型,美国AI监管混乱引发企业隐忧
微软押注企业AI需要工程师而非庞大销售团队
Anthropic揭开Claude AI黑箱:J-space技术带来模型内部可见性突破
英格兰银行获授权监管亚马逊、谷歌等科技巨头
酷睿Ultra战力Plus,英特尔携九大合作伙伴亮相Bilibili World 2026
iOS 26.5.2正式发布,包含逾20项安全修复,Claude协助发现漏洞
