
深度学习,跑在公有云还是本地更划算?
这些年来
围绕私有云与公有云的辩论
“成本”二字是绕也绕不开的话题
直到越来越多的研究表明
公有云并不比本地便宜
有时甚至可能更贵
这个争论才逐渐平息
但对于特殊的
深度学习应用呢
跑在公有云是否会比本地便宜?
云是托管AI开发和生产的最经济方式吗?Moor Insights&Strategy高级分析师Karl Freund认为,最好的方案取决于你在AI旅程中的位置、你将如何密集地建立你的AI能力,以及期望实现的成果。
为何云对AI有如此吸引力?
云服务提供商(CSP)拥有广泛的开发工具组合和预训练的深度神经网络,用于语音、文本、图像和翻译处理。例如,微软Azure提供了大量个预训练的网络和工具,可以被你的云托管应用程序作为API访问。
许多模型甚至可以用用户自己的数据进行定制,如特定的词汇或图像。谷歌也有一连串相当惊人的工具。比如它的AutoML可以自动构建深度学习神经网络,在某些情况下可以节省大量时间。

所有这些工具都有几个共同点。首先,它们使构建AI应用看起来非常容易。由于大多数公司都在努力为AI项目配备员工,因此这一点非常有吸引力。
其次,它们提供易用性,承诺在一个充满相对晦涩难懂的技术的领域中点击即可使用。但是,所有这些服务都有一个陷阱——他们要求你在他们的云中开发应用程序,并在他们的云中运行。
因此,这些服务具有极大的“绑定”特性。如果你使用微软的预训练的DNN进行图像处理,你不能轻易在自己的服务器上运行所产生的应用程序。你可能永远不会在非谷歌的数据中心看到谷歌的TPU,也无法使用谷歌的AutoML工具。

“绑定”本身并不一定是件坏事。但这里有一个问题:很多AI开发,特别是训练深度学习神经网络,最终需要大量的计算。此外,你不会停止训练一个(有用的)网络,你需要用新的数据和功能来不断保持它的“新鲜度”。
我所看到的公开研究表明,这种水平的计算在云中可能变得相当昂贵,成本是建立自己的私有云来训练和运行神经网络的2-3倍。
因此,对于小型,未知或可变的计算要求,云计算是有意义的,但是对于连续的、大规模深度学习而言,使用本地基础设施可节省大量成本。而且除了成本因素以外,还有更多原因需要使用自我托管。
01部署
启动一个AI项目可能需要大量的时间、精力和费用。云AI服务可以大大减少开始时的痛苦,不过一些硬件供应商也在提供硬件和软件的捆绑,力求AI的部署变得简单。

*例如,戴尔科技针对深度和机器学习推出了 "AI就绪型解决方案",其配备的完整GPU和集成软件栈,专为降低部署AI门槛而设计。
02数据安全
一些行业受到严格的监管,需要内部的基础设施。如金融行业,则认为将敏感信息放入云中风险太大。
03数据引力
这是对一些企业最重要的因素。简单说,如果你的重要数据在云中,你应该建立你的AI,并把你的应用程序也放在那里。但如果你的重要数据放在企业内部,数据传输的麻烦和成本可能是繁重的,特别是考虑到神经网络训练数据集的巨大规模。因此,在内部建立你的人工智能也是有意义的。

结 论
在哪里训练和运行AI是一个深思熟虑的决定。这里的问题是,通常在你的开发道路上走得很远,才能确定所需基础设施的大小(服务器的数量、GPU的数量、存储的类型等)。
一个常见的选择是在公有云中开始你的模型实验和早期开发,并制定一个带有预定义的退出计划,告诉你是否以及何时应该把工作搬回家。这包括了解CSP的机器学习服务的好处,以及如果你决定把所有东西都搬到自己的硬件上,你将如何取代它们。

省时省力还省心
从选好一个硬件供应商开始
AI正在革新我们的未来,而现在才刚刚起步。如同Karl Freund所认为的:本地AI基础设施可以比公有云更具经济效益。如果您计划在AI领域进行大量投资,一个好的硬件供应商(比如戴尔科技集团)不仅可以切合您的需要,其中一些服务更可以相当实惠。
凭借丰富的IT硬件组合,以及广泛的合作伙伴生态系统,戴尔科技正协助客户简化并积极推动数据科学及AI项目,无论是机器学习项目还是深度学习项目,涵盖的部署范围包括IoT网关、工作站、服务器、存储、AI就绪解决方案和HPC等。
用于机器学习的硬件
针对机器学习项目,戴尔易安信PowerEdge R750或R740xd是理想的平台。这些通用的2U服务器支持加速器和大容量存储,为后续的深度学习项目提供了未来的保障,其中xd版本还支持额外的存储容量。AI就绪型解决方案
戴尔科技提供预配置的AI就绪解决方案,可简化配置过程,降低成本,并加快部署分布式多节点机器学习和深度学习集群。这些集成系统对硬件、软件和服务进行了优化,有助于AI工作人员快速投入到生产并产生结果。用于AI的存储
存储性能对于机器学习项目的性能平衡至关重要,戴尔科技提供广泛的全闪存和混合存储产品组合,可以满足AI的苛刻要求,这包括戴尔易安信PowerScale和ECS的存储以及采用NFS和Lustre的分布式存储解决方案。

此外,还有当下热门的戴尔科技最新AI服务器——PowerEdge XE8545。其搭载的最新AMD米兰CPU、第三代NVlink - SMX4以及NVIDIA A100 40/80GB GPU,无不显示出这是成为尖端机器学习模型,复杂的高性能计算(HPC)和GPU虚拟化的理想选择。
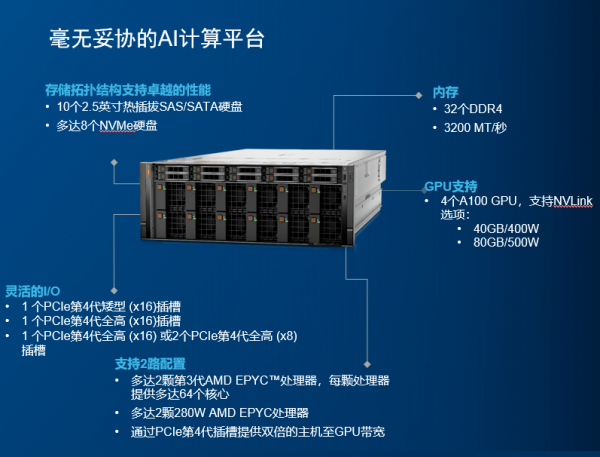
下面来看这款服务器的强大之处
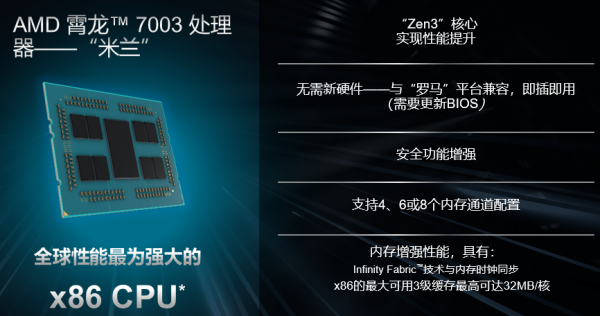
1AMD米兰CPU
XE8545配备了2颗地表最强的7nm Zen3架构的AMD第三代EPYC处理器。霄龙处理器一路走来,用自己的实力在服务器处理器市场牢牢的站稳了脚,高性价吸引了不少用户的目光。
2第三代NVLink-SXM4
XE8545 GPU内部采用NVIDIA第三代NVLink互联。其技术可提供更高带宽和更多链路,并可提升多GPU系统配置的可扩展性,故而可以解决互联问题。
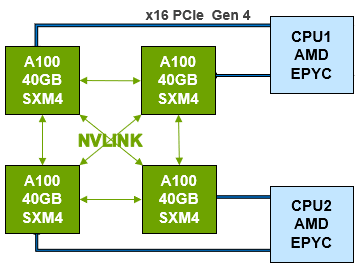
单个NVIDIA A100 Tensor核心GPU支持多达12个第三代NVLink 连接,总带宽为每秒600 千兆字节(GB/秒),几乎是PCIe Gen 4带宽的10倍。

NVIDIA DGX™ A100等服务器可利用这项技术来提高可扩展性,进而实现非常快速的深度学习训练。NVLink也可用于 PCIe版A100的双GPU配置。
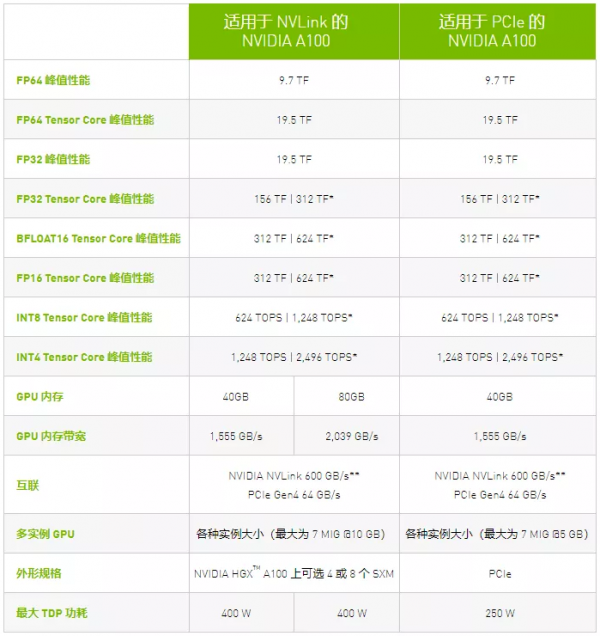
▲点击查看清晰图片
我们可以看出第三代NVLink的带宽几乎是PCIe Gen4的10倍,用第三代NVLink互联的A100在能够达到的最大功耗和显存上也远远高于PCIe Gen4互联的A100,是真正的灵活型性能怪兽。
3NVIDIA A100 40/80GB GPU
XE8545内部支持多达四个A100 GPU,性能极其强大。
A100引入了突破性的功能来优化推理工作负载。它能在从FP32到INT4的整个精度范围内进行加速。多实例GPU (MIG)技术允许多个网络同时基于单个A100运行,从而优化计算资源的利用率。在A100其他推理性能增益的基础之上,仅结构化稀疏支持一项就能带来高达两倍的性能提升。
在BERT等先进的对话式AI模型上,A100可将推理吞吐量提升到高达CPU的249倍。
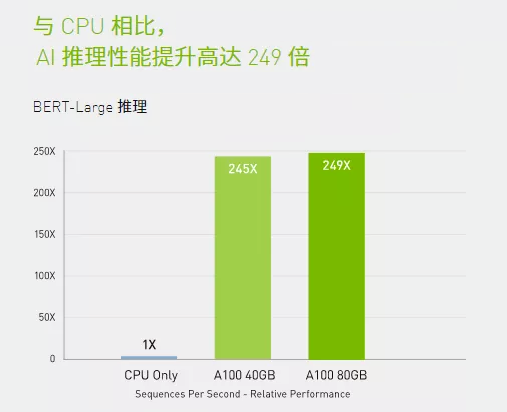
在受到批量大小限制的极复杂模型(例如用于先进自动语音识别用途的RNN-T)上,显存容量有所增加的A100 80GB能使每个MIG的大小增加一倍(达到10GB),并提供比A100 40GB高1.2倍的吞吐量。
NVIDIA产品的出色性能在MLPerf推理测试中得到验证。A100再将性能提升了20倍,进一步扩大了这种性能优势。
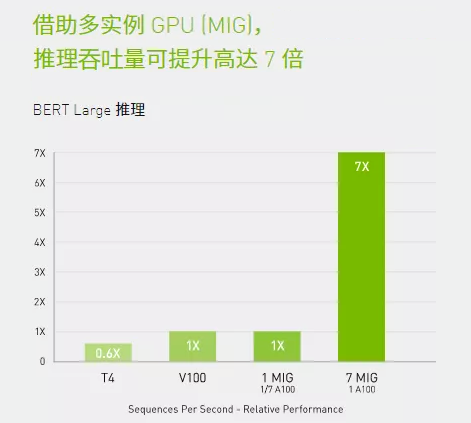
A100结合MIG技术可以更大限度地提高GPU加速的基础设施的利用率。借助MIG,A100 GPU可划分为多达7个独立实例,让多个用户都能使用GPU加速功能。使用A100 40GB GPU,每个MIG实例最多可以分配5GB,而随着A100 80GB增加的GPU内存容量,每个实例将增加一倍达到10GB。
除了强大的XE8545服务器外,戴尔科技还有全系列的AMD服务器供您选择。更详细的产品,欢迎联系戴尔官方企采网采购专线400-884-6610,或者联系您的客户经理。

尊敬的读者
劳动节福利火热派送中
4月24日-5月14日
超炫新品0元试用
到手无需归还
快来扫描下方二维码
或点击文末阅读原文
速速参与活动

来源:戴尔
好文章,需要你的鼓励


SanDisk重塑经典SSD品牌:WD Black和Blue正式更名为Optimus系列
西部数据闪存业务分拆后,SanDisk宣布将停用广受欢迎的WD Black和Blue品牌,推出全新的SanDisk Optimus系列NVMe产品线。WD Blue驱动器将更名为SanDisk Optimus,而高端WD Black驱动器将分别更名为Optimus GX和GX Pro。尽管品牌变更,底层硬件和供应链保持不变。然而受全球内存短缺影响,预计2026年第一季度客户端SSD价格可能上涨超过40%。

上海AI实验室研究者想出妙招:让AI像优秀学生一样高效思考,告别“想太多“毛病
上海AI实验室开发RePro训练方法,通过将AI推理过程类比为优化问题,教会AI避免过度思考。该方法通过评估推理步骤的进步幅度和稳定性,显著提升了模型在数学、科学和编程任务上的表现,准确率提升5-6个百分点,同时大幅减少无效推理,为高效AI系统发展提供新思路。

福特汽车准备在车载系统中引入AI智能助手
福特汽车在2026年消费电子展上宣布将在车辆中引入AI助手技术。该AI助手最初将在福特和林肯智能手机应用中推出,从2027年开始成为新车型的原生功能。福特希望通过AI技术实现车辆个性化体验,提供基于位置、行为和车辆能力的智能服务。同时,福特将采用软件定义车辆架构,推出自研的高性能计算中心,提升信息娱乐、驾驶辅助等功能。

MIT团队让机器人终于不再“卡顿“:一种让机器人像人一样流畅反应的突破性技术
MIT团队开发的VLASH技术首次解决了机器人动作断续、反应迟缓的根本问题。通过"未来状态感知"让机器人边执行边思考,实现了最高2.03倍的速度提升和17.4倍的反应延迟改善,成功展示了机器人打乒乓球等高难度任务,为机器人在动态环境中的应用开辟了新可能性。
2021
04/29
17:23
分享
点赞

智能体驱动全球创新浪潮,微软携手前沿伙伴迈进消费电子新未来
达索系统在CES 2026上展示AI驱动的医疗创新, 重塑精准、可预测与个性化医疗
Arm 发布 20 项技术预测:洞见 2026 年及未来发
美光推出全球首款面向客户端计算的 PCIe 5.0 QLC SSD
SanDisk重塑经典SSD品牌:WD Black和Blue正式更名为Optimus系列
福特汽车准备在车载系统中引入AI智能助手
ChatGPT推出健康模式:结合医疗数据提供个性化建议
福特推出AI数字助理及新一代BlueCruise自动驾驶技术
联想Legion Pro可卷曲概念机展现移动大屏游戏新体验
印度和新加坡在智能体AI采用方面超越全球同行
华硕CES 2026新品:更小巧的ProArt GoPro笔记本和升级版Zenbook Duo
n8n警告CVSS满分漏洞影响自托管和云版本
