
工程师笔记︱如何实现带外批量部署
随着互联网的迅猛发展,依赖于互联网业务的公司都在不断的建设和扩充信息化后台,尤其x86平台的兴起,自动化部署一直是热门话题。
不过,很多用户还是喜欢把服务器设备进行统一的安装系统和配置部署,然后再把服务器发送到各地的IDC。其实这样一方面比较浪费人力时间,另一方面也增加用户的运输成本。
为此,本文特别介绍了戴尔易安信 OpenManage Enterprise的自动化部署方案,并提供了详细安装方法以解决这个难题,供相关人员参考。
外面的世界很精彩, DevOps、统一监控、带外管理、运维安全等新理念不断加速着IT人员的工作效率,同时,开源的工具(Kicistart、Cobbler、FAI等)的不断兴起,也极大推动了自动化部署的发展。
不工具虽好问题也不容忽视:
① 免费、开源,但没有商业支持和响应;
② 需要自行构建和维护这套集中化部署环境(买商业化产品也行,不过需要$$$);
③ 适用于集中化构建,对于多地IDC环境,存在网络多套方案管理复杂的诸多问题。
那么,基于上述开源方案的不足,在IT自动化需求越来越强烈的今天,有没有针对于多地IDC的场景,能够实现统一集中化的部署和管理,兼顾成本的方案呢?
回答是肯定的,那就是戴尔易安信OpenManage Enterprise(OME)的自动化部署方案!

下面笔者就给大家演示如何安装OME,通过它,让你管理IT更省心!
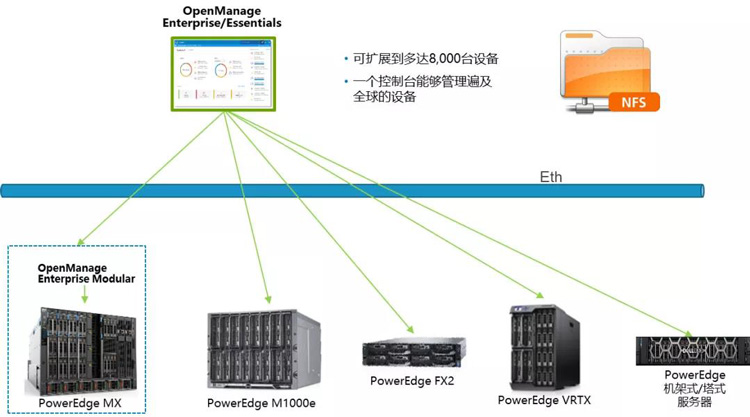
DELL EMC OpenManage Enterprise拓补图
实现自动化部署需五步走:
① OME软件+License
② 网络Network通过iDRAC卡实现网络管理和通信
③ NFS Server
④ KS定制化ISO(实现批量无人值守部署)
⑤ 批量任务实现自动化安装和部署
下面分解每一步的具体操作:
① 关于如何使用OME,可参见之前的微信文章:跟上节奏,现在数据中心管控平台都用它啦
② iDRAC网络连通,通过上架安装后,构建带外设备管理网络,分配IP地址等,实现网络连通。
③ NFS Server构建,NFS主要用户存放定制化好的ISO镜像,实现各地IDC服务器能够通过网络访问和加载ISO镜像文件,无需U盘和光盘介质。
④ KS定制ISO,本文主要使用启动ISO的介质制作,以Redhat为例,以ks.cfg文件的定义实现无人值守自动安装(关于ks.cfg文件,见文章底部附件1)。
⑤ 批量任务实现自动化部署步骤▼
1) 创建模板,本功能主要实现底层硬件BIOS、raid等参数的自动化部署;
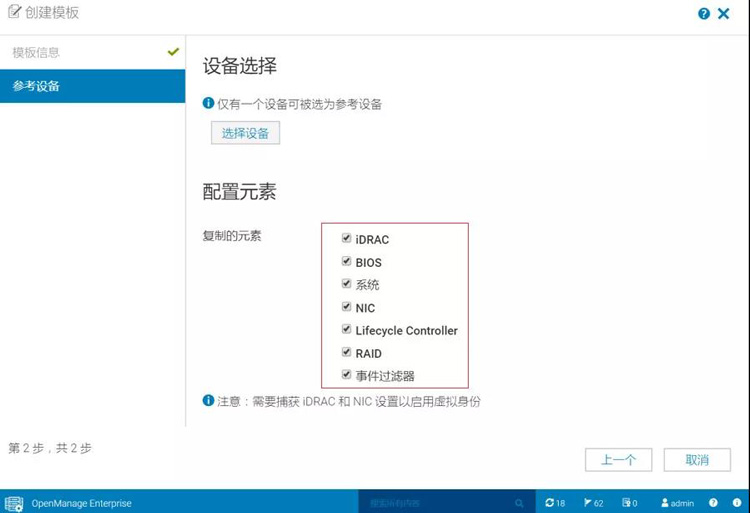
2) 加载部署任务,实现参数和OS的自动化部署任务执行(具体操作步骤如下图);
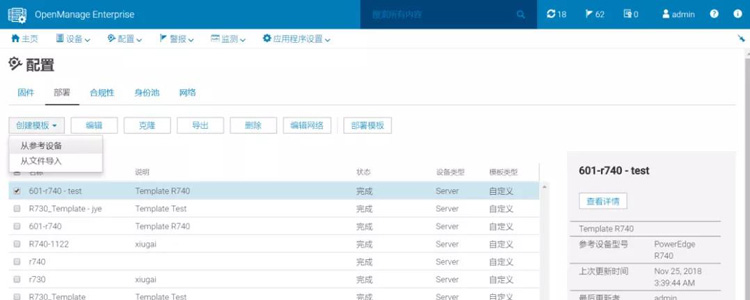
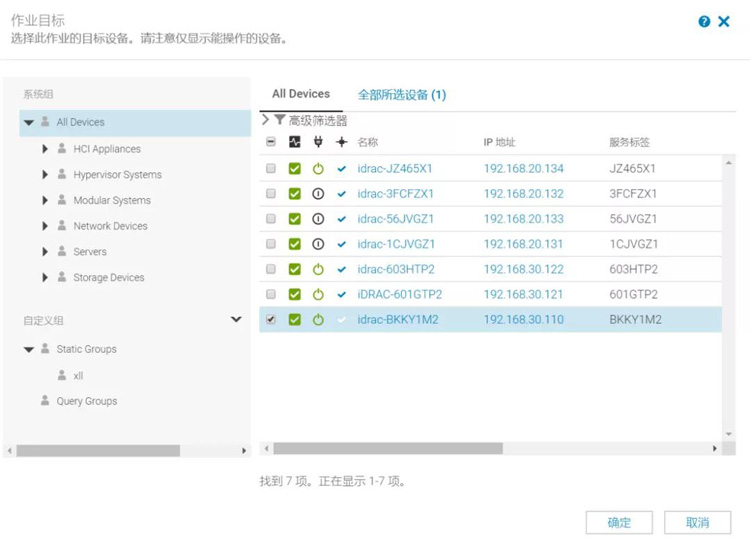
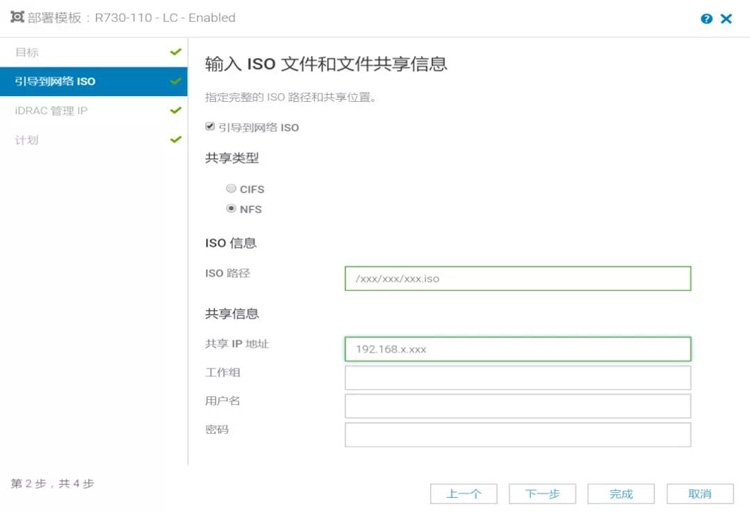
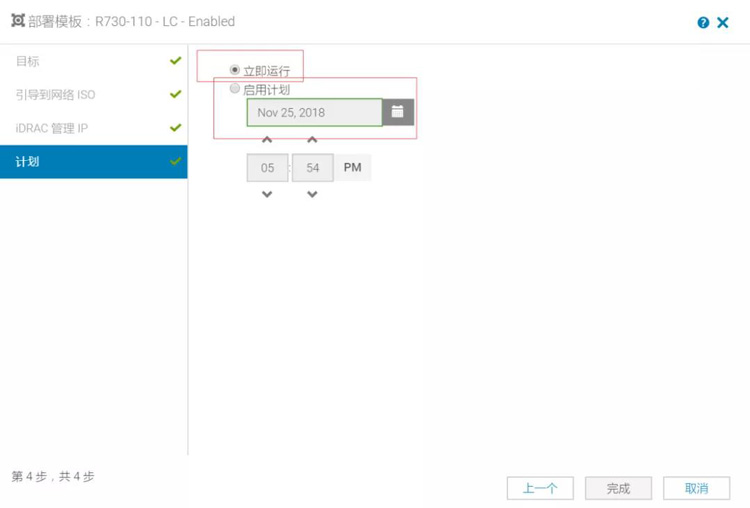
3)点击完成,系统就会自动去设置底层硬件配置以及OS的自动安装,同时有详细的日志输出,保证全过程监控。
是不是很简单?没有太多的花哨,简单而实用,图形化的操作方式,通过OME还可以统一管理设备信息,实现带外统一监控和管理,这一切是不是就是你想要的?还不赶快试试!

附件:
ks.cfg的设置模板(以Redhat 7.4为例):
#platform=x86, AMD64, or Intel EM64T
#version=DEVEL
# Install OS instead of upgrade
install
# Keyboard layouts
keyboard 'us'
# Root password
rootpw --iscrypted $XuZk4/B1$iZSYVp2Ab0B8H1IU.iNKX1
#new user with visudo
来源:至顶网云计算频道
好文章,需要你的鼓励


首个AI勒索软件攻击事件:幕后仍有人类参与
云安全公司Sysdig记录了首个"代理式勒索软件"案例——JadePuffer行动。AI代理自主完成入侵服务器、窃取凭证、加密文件并生成勒索信等全流程操作,速度惊人。然而,该攻击并非完全无人介入:人类仍负责选定目标、部署基础设施并提供初始访问凭证。研究人员暂未确认驱动该代理的具体模型,但指出随着运行成本降低,类似攻击规模可能快速扩大。

上交大与字节跳动联手:不用Docker也能训练出顶级代码AI,这项技术彻底打破了“必须有测试环境“的枷锁
上交大与字节跳动提出无环境代码AI验证器Dockerless,无需Docker测试环境即可判断代码修复正确性,训练性能接近传统环境化方法。

英国机器人公司Humanoid推出强化学习系统,机器人操控可靠性提升至99.9%
英国机器人与AI公司Humanoid发布KinetIQ Ascend强化学习系统,目标是以人类速度甚至更快达到99.9%的操作可靠性。该系统通过试错学习,在多项工业任务中表现出色:在机器送料任务中吞吐量提升42%,拣货递物任务成功率从80%升至98%,双臂搬运任务成功率达99%,且所有成果仅需数天训练即可实现。该系统还展示出类似大语言模型的扩展规律,训练时间越长性能越稳定提升。

当AI“老师“拥有“小抄“却教不好“学生“——新加坡国立大学等机构联合攻克AI知识蒸馏核心难题
DOPD提出"特权幻觉"概念,通过动态路由机制区分AI知识蒸馏中的能力差距与信息差距,让小模型在某些任务上超越大模型教师。
2019
03/11
16:09
分享
点赞

英国机器人公司Humanoid推出强化学习系统,机器人操控可靠性提升至99.9%
Waabi AI驾驶系统无需重新训练即可迁移至沃尔沃自动驾驶卡车
Apptronik携手谷歌DeepMind开设机器人训练园区,加速人形机器人商用部署
一个自我进化的开源代码模型突然火了,单张显卡实测效果真不错
比亚迪旗舰电动轿车海豹08上市30小时锁单超6.5万辆
特斯拉司机高速公路上熟睡,驾驶员监控系统为何失效?
AI助手争夺战:苹果能成为最终赢家吗?
NHS App将引入AI分诊工具,助力缩短患者等待时间
Station F加速器助力欧洲AI创业公司崛起
橡树岭国家实验室与克利夫兰诊所联合模拟聚变反应堆材料化学
Even Realities完成1.5亿美元融资,估值达10亿美元
数据中心会造成空气污染吗?关键在于电力来源
