
工程师笔记|服务器OS升级找不到网卡怎么办?
在UEFI方式下,使用网卡对高密度服务器上的OS进行升级时,设备设置里突然找不到网卡了怎么办?本文依托戴尔易安信PowerEdge C6420,以Linux操作系统为例,实际演示了遇到此种状况该如何解决,供相关人员参考。
一背景:
某客户在去年购买了戴尔易安信的高密度服务器PowerEdge C6420,此双路服务器在一个超高密度的2U机箱中提供多达4台独立热插拔,具备充足的计算、内存、存储、连接和机箱选项,配置灵活,在I/O方面支持OCP标准的25G网卡,可以满足客户高带宽、低延迟的需求。

春节过后,客户要升级OS,启用UEFI方式安装。在启用UEFI的过程中,遇到了一个问题:
Device Settings中看不到Mellanox 25G网卡▼
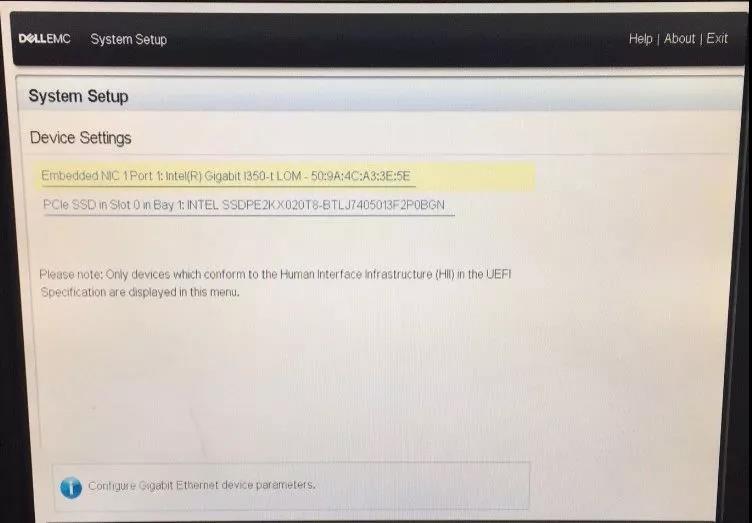
这下真是巧夫难为无米之炊了,要利用网卡进行服务器OS升级,结果却找不到对网卡操作的选项,很多人面对这种情形就进行不下去了。不过别着急,都是有解决办法滴,请查收下面这套有图有字的详细攻略。
二解决方法(以Linux操作系统为例)
① 从Mellanox官网下载MFT工具:
http://www.mellanox.com/page/management_tools
② 选择Linux版本的RPM包▼:
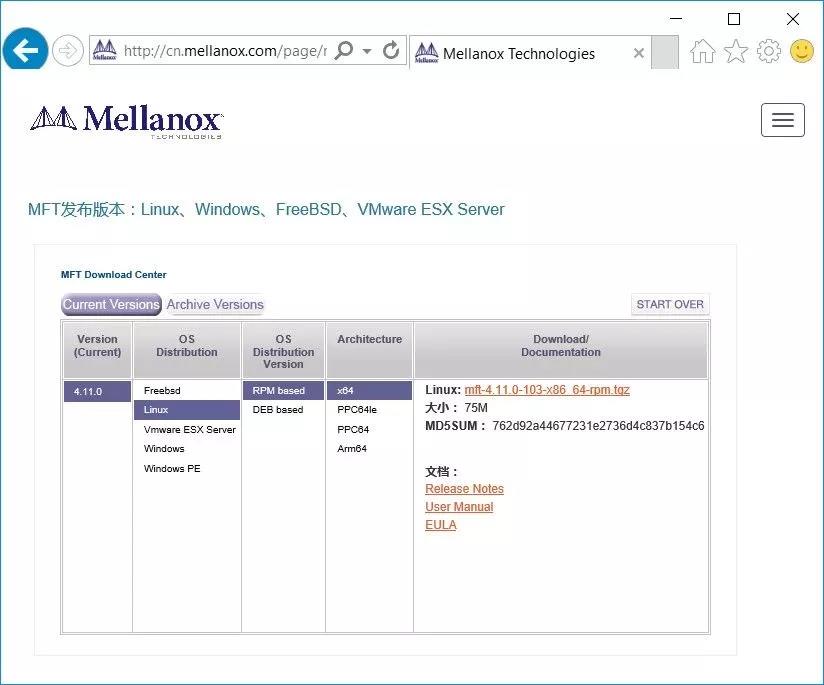
③ 完成下载后,将其拷贝到Linux中,并进行解压:
tar zxvf mft-4.11.0-103-x86_64-rpm.tgz
④ 然后开始安装MFT工具▼
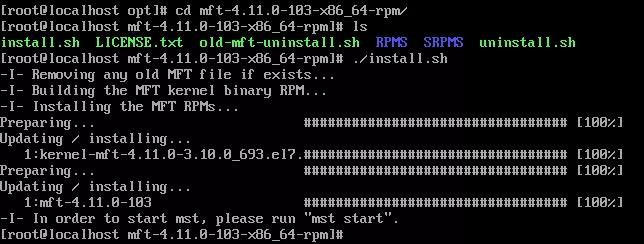
⑤ 安装完成后,启用MFT工具▼
mst start

⑥ 获取device ID▼
mst status
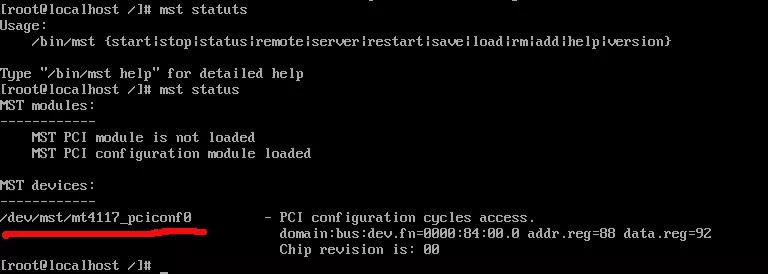
设备名固定为【mt4117_pciconf0】
⑦ 依次执行如下命令▼
mlxconfig -d /dev/mst/mt4117_pciconf0 set UEFI_HII_EN=1
mlxconfig -d /dev/mst/mt4117_pciconf0.1 set UEFI_HII_EN=1
mlxconfig -d /dev/mst/mt4117_pciconf0 set EXP_ROM_UEFI_x86_ENABLE=1mlxconfig -d /dev/mst/mt4117_pciconf0.1 set EXP_ROM_UEFI_x86_ENABLE =1---->执行:mlxconfig -d /dev/mst/mt4117_pciconf0 set UEFI_HII_EN=1
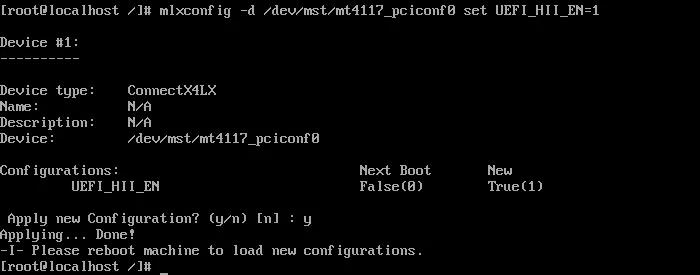
执行: mlxconfig -d /dev/mst/mt4117_pciconf0.1 set UEFI_HII_EN=1
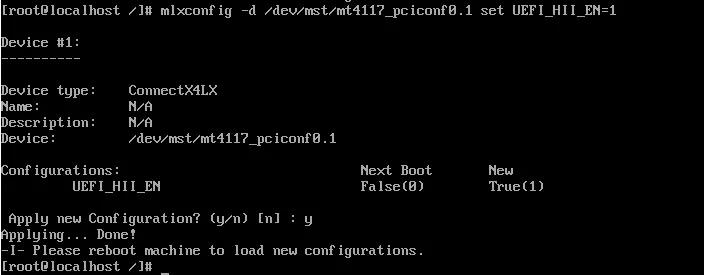
执行:mlxconfig -d /dev/mst/mt4117_pciconf0 set EXP_ROM_UEFI_x86_ENABLE=1
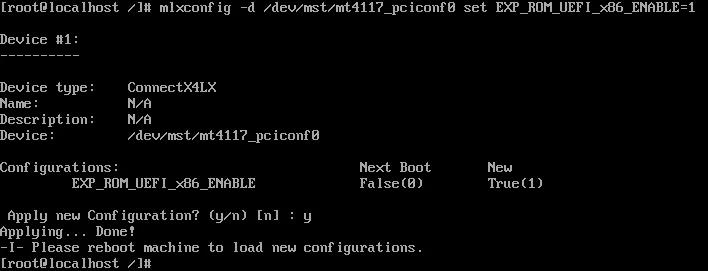
执行:mlxconfig -d /dev/mst/mt4117_pciconf0.1 set EXP_ROM_UEFI_x86_ENABLE =1

⑧ 完成以上操作后,重启服务器,进入BIOS界面▼
此时,在“Device Settings”界面里,就可以看到Mellanox网卡啦。

⑨ 看到UEFI网卡后,就可以进行网口的PXE设置了▼

三适用条件:
① 适用的物料:
Mellanox Connect X4 LX-EN 双端口 25G SFP+,PCIe3.0x8,OCP 夹层适配器 - DSS RESTRICTED(9R8DF)
② 适用机型:
PowerEdge C6420、PowerEdge R540、PowerEdge R740xd2、PowerEdge R7415、PowerEdge R6415
至此,问题已经圆满解决了。如果你也遇到此类问题,不妨试试这里介绍的方法吧!
来源:至顶网云计算频道
好文章,需要你的鼓励


首个AI勒索软件攻击事件:幕后仍有人类参与
云安全公司Sysdig记录了首个"代理式勒索软件"案例——JadePuffer行动。AI代理自主完成入侵服务器、窃取凭证、加密文件并生成勒索信等全流程操作,速度惊人。然而,该攻击并非完全无人介入:人类仍负责选定目标、部署基础设施并提供初始访问凭证。研究人员暂未确认驱动该代理的具体模型,但指出随着运行成本降低,类似攻击规模可能快速扩大。

卫星地图也能“按图索骥“?圣路易斯华盛顿大学研发出能读懂地图符号的AI图像生成系统
TerraDiT-Ω是圣路易斯华盛顿大学研发的卫星图像生成系统,能直接读取多边形、折线等地图原生符号生成高保真卫星图像,标注越精细效果越好。

英国机器人公司Humanoid推出强化学习系统,机器人操控可靠性提升至99.9%
英国机器人与AI公司Humanoid发布KinetIQ Ascend强化学习系统,目标是以人类速度甚至更快达到99.9%的操作可靠性。该系统通过试错学习,在多项工业任务中表现出色:在机器送料任务中吞吐量提升42%,拣货递物任务成功率从80%升至98%,双臂搬运任务成功率达99%,且所有成果仅需数天训练即可实现。该系统还展示出类似大语言模型的扩展规律,训练时间越长性能越稳定提升。

天津大学与上海人工智能实验室联手:让AI同时“读懂“和“模拟“人类大脑的视觉思维
BrainJanus是由天津大学与上海人工智能实验室联合提出的统一大脑模型,首次在单一自回归框架内实现大脑信号与图像、语言的双向任意转换,并揭示了大脑编码语义级评估的系统性漏洞。
2019
03/18
17:54
分享
点赞

英国机器人公司Humanoid推出强化学习系统,机器人操控可靠性提升至99.9%
Waabi AI驾驶系统无需重新训练即可迁移至沃尔沃自动驾驶卡车
Apptronik携手谷歌DeepMind开设机器人训练园区,加速人形机器人商用部署
一个自我进化的开源代码模型突然火了,单张显卡实测效果真不错
比亚迪旗舰电动轿车海豹08上市30小时锁单超6.5万辆
特斯拉司机高速公路上熟睡,驾驶员监控系统为何失效?
AI助手争夺战:苹果能成为最终赢家吗?
NHS App将引入AI分诊工具,助力缩短患者等待时间
Station F加速器助力欧洲AI创业公司崛起
橡树岭国家实验室与克利夫兰诊所联合模拟聚变反应堆材料化学
Even Realities完成1.5亿美元融资,估值达10亿美元
数据中心会造成空气污染吗?关键在于电力来源
