
IoT前沿|5G时代下,大数据存储面临的三大挑战
为什么开设“IoT前沿”专栏呢?事情是这样的:
一个月前,小编在戴尔科技集团知乎号(知乎搜索戴尔科技集团)回答了一个问题——
“开源分布式流存储Pravega前景怎么样?”
没想到回答发出之后,得到了大家的点赞和积极互动!
知乎问答
选取其中一些评论,看看大家在讨论什么▼
知乎前排网友:
@Sky快跑:不懂…什么叫原生流存储?
@常平:其实是专门针对流数据这样的数据类型而设计的存储系统,支持流数据的原生属性。
@Sky快跑:比较好奇流数据的原生属性是什么?_?
@常平:“流数据是一组顺序、大量、快速、连续到达的数据序列,一般情况下,数据流可被视为一个随时间延续而无限增长的动态数据集合。应用于网络监控、传感器网络、航空航天、气象测控和金融服务等领域” - 来源xx百科。用人话来说就是 自带 “标签 指标 时间戳”,以事件为单位特点是无限多,传输场景复杂。
@Sky快跑:感谢回复,看起来就像持久存储上面加了一层kafka?无限是指可以无限延续并且无限回溯?
@常平:有点类似kafka,但是kafka定位是消息系统,而这个是存储系统。无限是指数据可以无限的往里头存,无限延续。
▲可见,对于新技术,大家都有着非常强烈热情。而随着5G时代的来临,无论是投资者、企业家还是创业者都在加紧备战,以期在下一个十年中抓住最重要的机会。因此,为了方便大家了解前沿技术动态,小编也把这个回答也发布在这里,并特别开设“IoT前沿”专栏,向大家介绍戴尔科技集团的最新技术情报。快人一步,方能致胜未来!
作者简介

滕昱
滕昱:就职于Dell EMC中国研发集团,非结构化数据存储部门团队并担任软件开发总监。2007年加入Dell EMC以后一直专注于分布式存储领域。参加并领导了中国研发团队参与两代Dell EMC对象存储产品的研发工作并取得商业上成功。从2017年开始,兼任Streaming存储和实时计算系统的设计开发与领导工作。

周煜敏
周煜敏:复旦大学计算机专业研究生,从本科起就参与Dell EMC分布式对象存储的实习工作。现参与Flink相关领域研发工作。
工业物联网,车联网和实时欺诈风控的需求正在飞速发展,越来越多的企业新应用需要的是快速响应客户需求,并同时学习和适应不断变化的行为模式。同时,随着5G网络、容器云、高性能存储硬件水平的不断提高,数据增长进入了空前的发展阶段。
和以往不同的是,无处不在的物联网、自动驾驶汽车等边缘计算所产生的数据源源不断,就像开着的水管,数据源一直在流出。

这就给当前大数据处理系统(无论何种架构)提出了一个问题,即:
计算是原生的流计算,而存储却不是原生的流存储
当前大数据存储主要存在三大问题
下图是目前大数据处理平台最常见的Lambda架构,它的优势在于满足了实时处理与批处理需求,但是,从存储的角度看其缺点也很明显,可以总结为如下三点▼:
① 实时处理、批处理不统一,不同的处理路径采用了不同的存储组件,增加了系统的复杂度,导致了开发人员的额外学习成本和工作量。
② 数据存储多组件化、多份化,如下图,同样的数据会被存储在Elastic Search 、S3对象存储系统、Kafka等多种异构的系统中,而且考虑到数据的可靠性,数据还都是多份冗余的,这就极大的增加了用户的存储成本。而往往对于企业用户来说,0.1%的存储冗余都意味着损失。
③ 系统里存储的组件太多太复杂,也增加了使用的运维成本。并且大部分现有的开源项目还处于“强运维”的产品阶段,对于企业用户来说又是很大的开销。

Lambda架构
每种类型的数据都有其原生的属性和常用访问模式,对应有最佳的适用场景以及最合适的存储系统。为了解决如上提出的三个问题:降低开发成本、减少存储成本与减少运维成本,自然也就需要新的存储类型。在这里,我们将从最新的数据类型出发,探讨5G时代下数据存储新思路。
第四种存储类型:流存储
从存储的视角来说,存储架构的设计需要首先明确所存储的数据的特点。在物联网、自动驾驶汽车、金融等实时应用场景中,所需要存储的数据一般被称之为“流数据”,流数据一般被定义为:
流数据是一组顺序、大量、快速、连续到达的数据序列,一般情况下,数据流可被视为一个随时间延续而无限增长的动态数据集合。
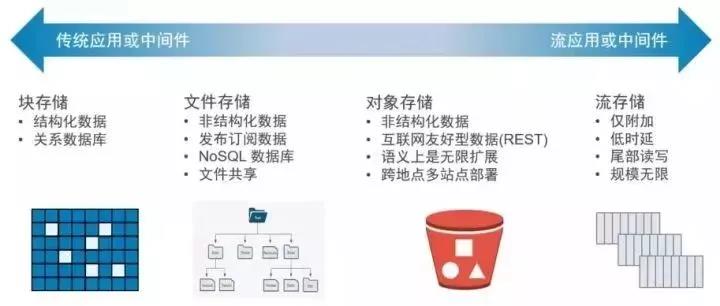
四大存储类型
上图所示▲,我们将流数据定义为第四种数据类型,从左到右分布着四种最常见的的存储类型。传统数据库这类基于事务的程序适合采用块存储系统。文件共享场景下需要在用户间共享文件进行读写操作,因此适合采用分布式文件 (NAS) 存储系统。而需要无限扩展并支持REST接口读写的非结构化的的图像/音视频文件则非常适合采用对象存储系统。
而针对流数据的应用场景,就需要流数据存储满足以下需求:
-
低延时:在高并发条件下 <10ms 的读写延时。
-
仅处理一次:即使客户端、服务器或网络出现故障,也确保每个事件都被处理且只被处理一次。
-
顺序保证:可以提供严格有序的数据访问模式
-
检查点:确保每个读客户端 / 上层应用能保存和恢复原来的使用状态
在物联网的世界,数据是实时的,分析也是实时的。获得业务洞察以赢得价值还是错失关键机会,对企业来说也许只有几毫秒的差距,而真正的流式数据处理可以减少传统的小批量分析方法的宝贵时间。
为此,戴尔科技集团IoT部门的团队重新思考了流式数据处理和存储规则,为这一场景重新设计了新的存储类型,即原生的流存储,就这样“Pravega”诞生了。

本期内容我们主要介绍了,当前大数据存储在5G时代下面临的挑战,以及需要用怎样的存储类型来满足新的数据类型的要求,由此引出了Pravega的诞生。今天是个开头,在下一期的“IoT前沿”中,我们将重点介绍Pravega的优势和特点,以及Pravega诞生之前数据处理架构的发展。欢迎大家保持关注,下一期见~
来源:至顶网云计算频道
好文章,需要你的鼓励


首个AI勒索软件攻击事件:幕后仍有人类参与
云安全公司Sysdig记录了首个"代理式勒索软件"案例——JadePuffer行动。AI代理自主完成入侵服务器、窃取凭证、加密文件并生成勒索信等全流程操作,速度惊人。然而,该攻击并非完全无人介入:人类仍负责选定目标、部署基础设施并提供初始访问凭证。研究人员暂未确认驱动该代理的具体模型,但指出随着运行成本降低,类似攻击规模可能快速扩大。

卫星地图也能“按图索骥“?圣路易斯华盛顿大学研发出能读懂地图符号的AI图像生成系统
TerraDiT-Ω是圣路易斯华盛顿大学研发的卫星图像生成系统,能直接读取多边形、折线等地图原生符号生成高保真卫星图像,标注越精细效果越好。

英国机器人公司Humanoid推出强化学习系统,机器人操控可靠性提升至99.9%
英国机器人与AI公司Humanoid发布KinetIQ Ascend强化学习系统,目标是以人类速度甚至更快达到99.9%的操作可靠性。该系统通过试错学习,在多项工业任务中表现出色:在机器送料任务中吞吐量提升42%,拣货递物任务成功率从80%升至98%,双臂搬运任务成功率达99%,且所有成果仅需数天训练即可实现。该系统还展示出类似大语言模型的扩展规律,训练时间越长性能越稳定提升。

天津大学与上海人工智能实验室联手:让AI同时“读懂“和“模拟“人类大脑的视觉思维
BrainJanus是由天津大学与上海人工智能实验室联合提出的统一大脑模型,首次在单一自回归框架内实现大脑信号与图像、语言的双向任意转换,并揭示了大脑编码语义级评估的系统性漏洞。
2019
03/25
14:20
分享
点赞

英国机器人公司Humanoid推出强化学习系统,机器人操控可靠性提升至99.9%
Waabi AI驾驶系统无需重新训练即可迁移至沃尔沃自动驾驶卡车
Apptronik携手谷歌DeepMind开设机器人训练园区,加速人形机器人商用部署
一个自我进化的开源代码模型突然火了,单张显卡实测效果真不错
比亚迪旗舰电动轿车海豹08上市30小时锁单超6.5万辆
特斯拉司机高速公路上熟睡,驾驶员监控系统为何失效?
AI助手争夺战:苹果能成为最终赢家吗?
NHS App将引入AI分诊工具,助力缩短患者等待时间
Station F加速器助力欧洲AI创业公司崛起
橡树岭国家实验室与克利夫兰诊所联合模拟聚变反应堆材料化学
Even Realities完成1.5亿美元融资,估值达10亿美元
数据中心会造成空气污染吗?关键在于电力来源
