
数据就像开着的水管,要怎么同步存储?
随着5G时代到来,
无处不在的物联网、
自动驾驶汽车等在边缘产生的数据,
源源不断,就像开着的水管。
计算是原生的流计算,
而存储却不是原生的流存储。
这也就是为什么说原有的存储服务无法胜任新数据环境下的要求。
今天要谈的StateSynchronizer,
很好地解决了未来流数据环境下存储工作的难题。
一起跟随"逻辑狂人"来了解下吧!
???
文章导读
本文将从共享状态和一致性的角度出发,详细描述StateSynchronizer的整体架构、工作机制和实现细节。利用stream的天然特性,StateSynchronizer可以高效地确定出更新操作的全局顺序,并且从逻辑上实现了对共享状态的一致性更新与存储。由于stream访问的高效与轻量,StateSynchronizer特别适用于高并发 (>= 10000 clients) 的场景,并在此场景下可以作为替代ZooKeeper和etcd的解决方案。
StateSynchronizer作为开源分布式流存储平台Pravega的核心组件,不仅是Pravega公共API的一部分,许多Pravega内部组件也大量依赖StateSynchronizer共享状态,如ReaderGroup的元信息管理。并且我们可以基于StateSynchronizer实现更高级的一致性原语,例如跨stream的事务。
Pravega从入门到精通,从这里开始~
作者简介

蔡超前
蔡超前:华东理工大学计算机应用专业博士研究生,现就职于Dell EMC,6年搜索和分布式系统开发以及架构设计经验,现从事流相关的设计与研发工作。

滕昱
滕昱:就职于Dell EMC中国研发集团,非结构化数据存储部门团队并担任软件开发总监。2007年加入Dell EMC以后一直专注于分布式存储领域。参加并领导了中国研发团队参与两代Dell EMC对象存储产品的研发工作并取得商业上成功。从2017年开始,兼任Streaming存储和实时计算系统的设计开发与领导工作。
Pravega属于戴尔科技集团IoT战略下的一个子项目。该项目是从0开始构建,用于存储和分析来自各种物联网终端的大量数据,旨在实现实时决策。其结合了戴尔易安信PowerEdge服务器,并无缝集成到非结构化数据产品组合Isilon和Elastic Cloud Storage(ECS)中,同时拥抱Flink生态,以此为用户提供IoT所需的关键平台。
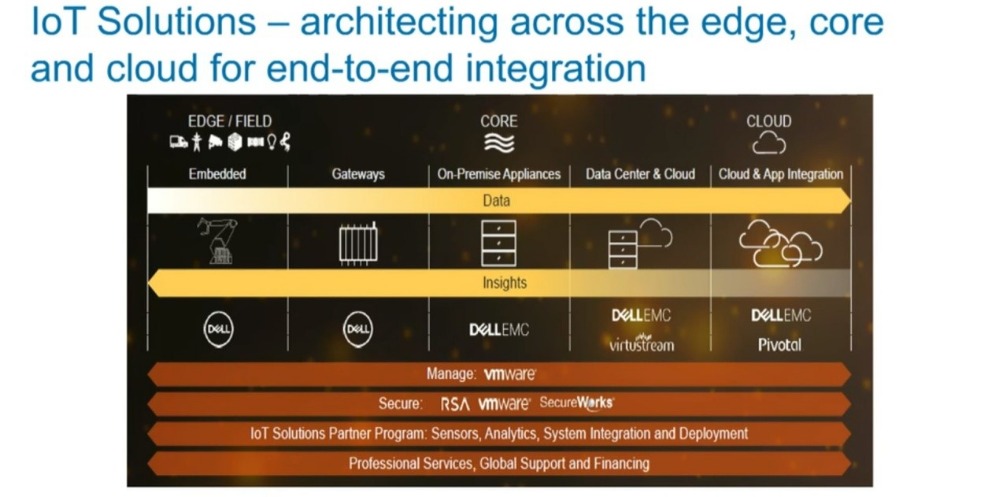
戴尔科技集团IoT解决方案集合了戴尔科技家族的力量,覆盖从边缘到核心再到云端
什么是 StateSynchronizer
(状态同步器)?
Pravega既可以被想象成是一组流存储相关的原语,因为它是实现数据持久化的一种方式,也可以被想象成是一个消息订阅 - 发布系统,因为通过使用reader,writer和ReaderGroup,它可以自适应地进行消息传递。(关于Pravega,读者可以从下方4篇文章中获取详细资料。)
《IoT前沿》系列文章
Pravega实现了各种不同的构建模块用以实现stream相关原语,StateSynchronizer就是其中之一,目的在于协调分布式的环境中的各个进程[2]。
从功能上看,StateSynchronizer为一组进程提供可靠的共享的状态存储服务:允许多个客户端同时读取和更新同一共享状态并保证一致性语义,同时提供数据的冗余和容错。从实现上看,StateSynchronizer使用一个stream为集群中运行的多个进程提供了共享状态的同步机制,这使得构建分布式应用变得更加简单。

StateSynchronizer的最大贡献在于它提供了一种stream原生的一致性存储方案。由于stream具有只允许追加(Append-Only)的特性,这使得大部分现有的存储服务都无法很好地应用于stream存储的场景。相比于传统的状态存储方案,stream原生的存储使得StateSynchronizer具有以下优点:
● 与常见的键值存储(Key/Value Store)不同,StateSynchronizer支持任意抽象的共享状态,而不仅仅局限于维护键值集合。
● 与常见的数据存储不同,StateSynchronizer以增量的方式维护了共享状态的整个变更历史,而不仅仅是维护共享状态的最新快照。这一特性不仅大大减少了网络传输开销,还使得客户端可以随时将共享状态回滚到任意历史时刻。
● 与常见的状态存储不同,StateSynchronizer的服务端既不存储共享状态本身也不负责对共享状态进行修改,所有共享状态的存储和计算都只发生在客户端本地。这一特性不仅节约了服务端的计算资源,还增加了状态计算的灵活性,例如:除了基本的CAS(Compare-And-Swap)语义,还支持高隔离级别的复杂事务。
● 与现有的基于乐观并发控制(Optimistic Concurrent Control, OCC)的存储系统不同,StateSynchronizer 可以不依赖多版本控制机制(Multi Version Concurrent Control, MVCC)。这意味着即使在极端高并发的场景下,状态更新的提交也永远不会因版本冲突而需要反复重试。
StateSynchronizer无意于也不可能在所有场景中替代传统的分布式键值存储组件,因为它的运行机制大量依赖stream的特性。但是,在具有stream原生存储和较强一致性需求的场景下,StateSynchronizer可能是一种比其它传统键值存储服务更为高效的选择。
开宗明义
“一致性”的不同语义
在不同的上下文环境中,“一致性”一词往往有着不同的语义。
在分布式存储和数据高可用(High Availability)相关的语境下,一致性通常指数据副本(Replica)的一致性:如何保证分布在不同机器上的数据副本内容不存在冲突,以及如何让客户端看起来就像在以原子的方式操作唯一的数据副本,即线性化(Linearizability)。常见的分布式存储组件往往依赖单一的Leader(主节点)确定出特定操作的全局顺序,例如:ZooKeeper和etcd都要求所有的写操作必须由Leader转发给其它数据副本。数据副本的一致性是分布式系统的难点,但却并不是一致性问题的全部。
脱离数据副本,在应用层的语境下,一致性通常指数据满足某种约束条件的不变性(Invariant),即:指的是从应用程序特定的视角出发,保证多个进程无论以怎样的顺序对共享状态进行修改,共享状态始终处于一种“正确的状态”,而这种正确性是由应用程序或业务自身定义的。
例如,对于一个交易系统而言,无论同时有多少个交易在进行,所有账户的收入与支出总和始终都应该是平衡的;又如,多进程操作(读/写)一个共享的计数器时,无论各进程以怎样的顺序读写计数器,计数器的终值应该始终与所有进程顺序依次读写计数器所得到的值相同。
参考文献[1]将这种一致性归类为“事务性的一致性(Transactional Consistency)”,而参考文献[2]则将此类一致性简单称为“涉及多对象和多操作的一致性”。应用层的数据一致性语义与数据副本的一致性语义完全不同,即使是一个满足线性化的分布式系统,也需要考虑应用层的数据一致性问题。
StateSynchronizer与
现有的一致性存储产品区别
目前常用的分布式键值存储服务,例如ZooKeeper和etcd,都可以看作是一种对共享状态进行存储和维护的组件,即所有键值所组成的集合构成了当前的共享状态。在数据副本层面,ZooKeeper和etcd都依赖共识(Consensus)算法提供一致性保证。ZooKeeper使用ZAB(ZooKeeper’s Atomic Broadcast)协议在各节点间对写操作的提交顺序达成共识。在广播阶段,ZAB协议的行为非常类似传统的两阶段提交协议。etcd则使用Raft协议在所有节点上确定出唯一的写操作序列。与ZAB协议不同,Raft协议每次可以确认出一段一致的提交序列,并且所有的提交动作都是隐式的。

在应用层数据层面,ZooKeeper和etcd都使用基于多版本控制机制的乐观并发控制提供最基础的一致性保证。一方面,虽然多版本控制机制提供了基本的CAS语义,但是在极端的高并发场景下仍因竞争而存在性能问题。另一方面,仅仅依靠多版本控制机制无法提供更加复杂的一致性语义,例如事务。
尽管在数据副本层面,ZooKeeper和etcd都提供很强的一致性语义,但对于应用层面的数据一致性却还有很大的提升空间:ZooKeeper无法以原子的方式执行一组相关操作,而etcd的事务仅支持有限的简单操作(简单逻辑判断,简单状态获取,但不允许对同一个键进行多次写操作)。
为应用层数据提供比现有的分布式存储组件更强的一致性语义(复杂事务)和更高的并发度是StateSynchronizer的主要目标,尤其是在stream原生场景下,因为传统的以随机访问为主的存储组件很难适配stream存储的顺序特性。得益于stream的自身特性,StateSynchronizer可以不依赖乐观并发控制和CAS语义,这意味着不会出现版本冲突也无需重试,从而更加适用于高并发的场景。在“无条件写”模式下,StateSynchronizer的理论更新提交速度等价于stream的写入速度。

与现有的绝大多数存储服务不同,StateSynchronizer反转了传统的数据存储模型:它并不存储共享状态本身,转而存储所有作用在共享状态上的更新操作。一方面,这一反转的数据模型直接抽象出了共享状态,使得共享状态不再局限于简单的键值存储,而可以推广到任意需要一致性语义的状态。另一方面,反转数据存储的同时还不可避免地反转了数据相关的操作,使得原本大量的服务端状态计算可以直接在客户端本地完成。这一特性不仅大大降低了服务端的资源消耗,同时也使得StateSynchronizer可以提供更灵活的更新操作和更强一致性语义:复杂事务。
在StateSynchronizer的框架中,客户端提交的所有更新操作都是以原子的方式顺序执行的,并且所有更新操作的执行都发生在本地。从逻辑上看,每一个更新操作都等价于一个本地事务操作。这也意味着客户端可以在更新操作中使用复杂的业务逻辑(几乎是不受限的操作,只要操作本身的作用是确定性的)而无需担心一致性问题。
总结
本文主要从状态共享和一致性的角度出发,详细描述了Pravega的状态同步组件StateSynchronizer的工作机制。StateSynchronizer支持分布式环境下的多进程同时读写共享状态,并提供一致性保证。
截至目前,我们已经花了5个篇幅来介绍Pravega,在下一期的内容里,我们将介绍StateSynchronizer的实现细节,欢迎大家持续关注,如何你有疑问,可在下方留言或知乎号上(见下方二维码)找到我们。下一期见~

扫码关注知乎号
你和戴尔易安信专家只有一条网线的距离~
参考文献:
[1] P. Viotti and M. Vukoli?, "Consistency in Non-Transactional Distributed Storage Systems," ACM Computing Surveys (CSUR), vol. 49, no. 1, 2016.
[2] P. Bailis, A. Davidson, A. Fekete, A. Ghodsi, J. M. Hellerstein and I. Stoica, "Highly available transactions: virtues and limitations," in Proceedings of the VLDB Endowment, 2013.
相关阅读推荐:别再被数据迷惑了,选存储前了解这些很重要
了解更多数字化转型方案查看此链接:
https://www.dellemc-solution.com/home/index.html
来源:戴尔
好文章,需要你的鼓励


AI智能体利用Langflow漏洞完成首例全自主勒索软件攻击
云安全公司Sysdig记录了首例由AI Agent全程自主执行的勒索软件攻击,将其命名为JadePuffer。该AI利用Langflow严重漏洞(CVE-2025-3248,评分9.8)入侵服务器,窃取OpenAI、AWS、阿里云等平台凭证,随后加密并删除目标数据库的1342条配置项,留下比特币勒索信。由于加密密钥随用随弃,付款也无法恢复数据。整个攻击过程超过600个独立操作步骤,AI还能在31秒内自主修复错误,无需人工介入。

延世大学与首尔大学联手:让AI真正“看懂“3D场景里的每一件物体
来自延世大学与首尔大学的研究提出将3D场景直接分解为以物体为单位的词元组,无需后处理即可实现场景编辑、语义检索和实例分割,语义存储量缩减140倍。

SK Hynix赴美IPO:乘AI存储需求东风,或募资280亿美元
韩国存储芯片巨头SK Hynix宣布计划在美国IPO,发行约1780万股,以上周五首尔收盘价计算,募资规模或达280亿美元。公司将以美国存托凭证(ADR)形式上市,每份ADR代表十分之一普通股,预计本周四定价、周五开始交易。受AI需求驱动,SK Hynix今年股价累计涨幅约260%,一季度营收同比增长近200%。AI系统对HBM、DRAM、NAND等存储芯片需求旺盛,市场供应持续紧张。

耶鲁大学与谷歌研究院联手:让AI学会“自知之明“,不再满嘴自信地胡说八道
耶鲁大学与谷歌研究院联合提出RLMF方法,通过元认知反馈让大语言模型学会准确判断自身不确定性,使AI在表达置信程度时更加诚实可靠,显著超越现有方法。
2019
05/23
14:49
分享
点赞

SK Hynix赴美IPO:乘AI存储需求东风,或募资280亿美元
首个AI勒索软件攻击事件:幕后仍有人类参与
Ambi Robotics与Pickle Robot携手推出AI机器人,实现仓库入库物流全流程自动化
英国机器人公司Humanoid推出强化学习系统,机器人操控可靠性提升至99.9%
Waabi AI驾驶系统无需重新训练即可迁移至沃尔沃自动驾驶卡车
Apptronik携手谷歌DeepMind开设机器人训练园区,加速人形机器人商用部署
一个自我进化的开源代码模型突然火了,单张显卡实测效果真不错
比亚迪旗舰电动轿车海豹08上市30小时锁单超6.5万辆
特斯拉司机高速公路上熟睡,驾驶员监控系统为何失效?
AI助手争夺战:苹果能成为最终赢家吗?
NHS App将引入AI分诊工具,助力缩短患者等待时间
Station F加速器助力欧洲AI创业公司崛起
