
2019年首份全球融合系统市场报告来啦!
就在昨天
IDC公布了今年第一季度的
全球融合系统市场报告
现在的超融合行业发展怎么样了?
大家都很期待
小编也立即将报告翻译完毕
热腾腾的
呈现给大家
???
来自IDC的2019年第一季度全球融合系统市场季度追踪报告显示,第一季度全球融合系统市场延续增长势头,收入同比增长19.3%,至37.5亿美元。
细分来看,经过认证的参考系统和集成基础设施市场在2019年第一季度创造了近14亿美元的收入,同比增长9.0%,占融合系统总收入的36.6%;集成平台的收入为5.56亿美元,同比下降13.3%;而超融合系统销售收入在本季度同比增长46.7%,实现了18亿美元的收入,已经占据融合系统总收入的48.6%,接近半壁江山。
对于超融合的强势增长,IDC基础设施平台和技术研究经理Sebastian Lagana点评道:
超融合基础设施仍然是融合系统市场的主要增长动力。降低运营复杂性、易于部署以及在混合云环境中的出色适应性,继续推动着超融合在广泛的客户和工作负载中的部署。”
以下是各厂商在本季度的具体表现
IDC的报告显示,在超融合系统方面,戴尔科技集团继续成为本季度的“领头羊”,行业占比32.2%,收入同比增长64%至5.86亿美元。不仅收入增速领跑大盘,且行业占比与后二位厂商进一步拉开差距,显示出戴尔科技超融合产品的强劲势头以及全球客户的极高认可。
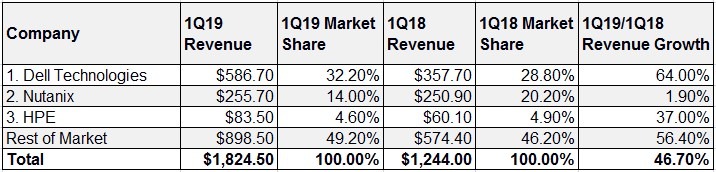
▲2019年第一季度全球超融合系统厂商收入、行业份额和增长(单位:百万美元)
来源:IDC 2019Q1融合系统市场报告
而在超融合软件方面,戴尔科技集团的另一位家族成员VMware也不负众望,在本季度拿下41.1%的行业份额,收入同比增长66.3%至7.50亿美元,增速同样领跑大盘。

▲2019年第一季度全球超融合软件厂商收入、行业份额和增长(单位:百万美元)
来源:IDC 2019Q1融合系统市场报告
越来越好的VxRail
总结这份2019年第一季度融合系统行业报告,对戴尔科技集团而言,无疑是要给一个大大赞。
超融合行业发展多年,早已经走过了最初的市场培育阶段,而是走向成熟。这也就意味着以往那个有个盒子,然后把软硬件打包在一起就能卖给客户的时代已经过去,到了真正比拼各厂商技术实力的时候。这一点从本次IDC报告的超融合软件部分就能明显看出:
其他厂商的行业份额相比去年同期下降,而头部厂商占比扩大。
超融合行业大浪淘沙,在各行各业都在步入数字化转型的关键节点,比拼的就是各家“硬实力”,而戴尔科技集团旗下戴尔易安信和VMware,分别作为各自领域的领导者,取得这份成绩实属应当。
就像戴尔科技集团董事长兼首席执行官迈克尔·戴尔所说:“我们满意但不满足。”

尽管VxRail已经集合了戴尔科技集团旗下戴尔易安信的PowerEdge服务器与存储,还有VMware的虚拟化,可谓含着金钥匙出生,但我们并不满足,而是让它越来越好。

去年,VMware宣布推出了VMware Cloud Foundation on VxRail,这是业界首个与VMware联合设计的混合云基础架构堆栈,它建立在Dell EMC与VMware联合设计的历史基础之上,为客户提供不同于任何其他运行VMware Cloud Foundation基础架构的体验。可将生命周期作为一个完整、自动化的、交钥匙的内部部署体验进行管理,从而大大降低风险并提高IT运营效率。

今年戴尔科技集团全球大会,VxRail也作为大会上重量级发布的VMware Cloud on Dell EMC和戴尔科技云平台的核心构建块。
戴尔科技云平台使企业和组织能够在数据中心和边缘环境中使用诸如公有云服务之类的基础架构,这使IT部门不必再负担基础架构管理和维护之类的基本任务,并且支持订阅式定价模式。VMware Cloud on Dell EMC通过混合云控制面提供了与公有云的双向连接,从而为客户带来关键应用和数据的可移植性。

简而言之
VxRail将不仅仅是超融合
而是成为客户未来面向多云环境下的重要基石

再次感谢用户对戴尔易安信的厚爱
我们将用不断优化产品与服务
为您的数字化未来保驾护航
来源:戴尔
好文章,需要你的鼓励


罗德岛大学海洋机器人实验室正式揭幕,推动自主海洋研究新里程
罗德岛大学于6月25日在纳拉甘西特湾校区举行水下剪彩仪式,正式启用新建的海洋机器人实验室。该实验室配备20×30英尺的测试水槽,是3亿美元校区振兴计划的重要里程碑。实验室将支持水下机器人研发与海洋自主探测技术,推动罗德岛蓝色经济发展。州长、议员及校方代表出席仪式,强调该设施将吸引顶尖人才,促进高校与产业界合作。

北京大学与腾讯混元联手破解AI图像生成的“两阶段诅咒“——GEAR框架让图像生成效率提升10倍
北京大学与腾讯混元提出GEAR框架,通过双轨软硬路径设计,首次实现VQ编码器与自回归生成器的端到端联合训练,图像生成收敛速度提升最高10倍。

SK Hynix赴美IPO拟募资280亿美元,AI芯片需求持续火热
韩国存储芯片巨头SK Hynix宣布将在美国发行约1780万股美国存托凭证(ADR),预计融资约280亿美元。受AI驱动的存储芯片需求激增,SK Hynix一季度营收同比增长近200%,股价年内涨幅超260%。此次上市若达成目标,将成为史上第二大IPO,仅次于SpaceX。SK Hynix与三星还承诺共同投资逾5.5亿美元扩建生产设施,以应对持续旺盛的AI存储需求。

当AI助手“听不懂“你说的话:意大利FBK研究所揭示语音大模型的多语言安全漏洞
意大利FBK研究所推出首个多语言真人声音语音AI安全基准REDVOX,测试八款主流模型发现:非英语用户面临近两倍于英语用户的安全风险,语音输入比文字输入更易触发有害回应。
2019
06/27
14:22
分享
点赞

AI 时代新标准:如何保障关键任务的可用性与安全?
罗德岛大学海洋机器人实验室正式揭幕,推动自主海洋研究新里程
SK Hynix赴美IPO拟募资280亿美元,AI芯片需求持续火热
AI智能体利用Langflow漏洞完成首例全自主勒索软件攻击
SK Hynix赴美IPO:乘AI存储需求东风,或募资280亿美元
首个AI勒索软件攻击事件:幕后仍有人类参与
Ambi Robotics与Pickle Robot携手推出AI机器人,实现仓库入库物流全流程自动化
英国机器人公司Humanoid推出强化学习系统,机器人操控可靠性提升至99.9%
Waabi AI驾驶系统无需重新训练即可迁移至沃尔沃自动驾驶卡车
Apptronik携手谷歌DeepMind开设机器人训练园区,加速人形机器人商用部署
一个自我进化的开源代码模型突然火了,单张显卡实测效果真不错
比亚迪旗舰电动轿车海豹08上市30小时锁单超6.5万辆
