
击败剩下的0.02%人类选手
今年10月30日
DeepMind在《自然》杂志上
发表的一篇论文
仿佛又一次把人们的视线
拉回了两年前的那场
“世纪大战”之中
不过,这回的主角不是
“阿尔法狗”(AlphaGo)
而是AlphaStar
这位《星际争霸2》玩家
在欧洲服务器击败了
99.8%人类选手

有同学听后不以为然
“也没有扫遍天下无敌手嘛。”
然而事实是
一局典型《星际争霸》游戏的
搜索空间大约是一盘典型
围棋棋局的101799640倍
而要击败剩下的0.02%人类选手
也只是个时间问题

从深蓝到AlphaGo
再到AlphaStar
过去10年,人工智能在机器视觉、
深度学习、自然语言处理
等领域取得了重大突破
而在这条道路上
计算力是重要的推动力
OpenAI在2018年一份研究报告显示:2012年起,AI消耗的计算力平均每3.43个月增长一倍,过去6年时间内已经增长30万倍。GPU计算是当下AI深度学习训练和推理计算的首选架构,FPGA与ASIC亦在积蓄力量。

戴尔科技集团持续投入到AI计算解决方案研究,并将我们的研究成果、效能测试、技术白皮书,分享给用户及TensorFlow、Caffe、MXNet等主流开源框架社区。戴尔易安信在DSS8440、C4140、R740、R740xd、R940xa、R840、R7425、T640、XR2等多款服务器上,提供超过50种AI GPU加速配置方案支持,总有一款可以满足您的需求。
全方位的AI GPU加速配置方案
总有一款可以满足您
DSS8440
DSS8440是戴尔易安信设计的一款动态机器学习加速平台,搭载2个Intel®Xeon®处理器可扩展系列,每个处理器最多24个内核/2个LGA3647/英特尔C620,专为机器学习应用程序和其他需要最高计算性能的高要求工作负载而设计。4U机箱可以支持最多8张戴尔投资AI芯片企业GraphcoreIPU ASIC加速卡,适合于各种AI计算环境下深度学习模型训练。DSS8440提供更强的环境适应能力,支持在35℃环境下205W CPU以及GPU加速器。

C4140
C4140是戴尔易安信为AI计算精心打造的另外一款智能计算神器。C4140机箱只有1U,却可以在有限的空间内支持4张最高性能的双宽GPU加速卡、本地NVMe SSD硬盘以及100Gb低延迟网卡,为用户提供极佳的数据中心空间GPU计算密度。

R940xa
当前很多复杂的AI应用场景,往往使用多种算法的集成学习,以达到更好的模型精度,解决小数据样本下的机器学习,比如工业产品外观缺陷检测。而不同算法可能会选择不同的计算介质,比如深度学习选择GPU,经典机器学习使用CPU。此时,戴尔易安信R940xa四路计算加速服务器,可以提供CPU与GPU 1:1的计算配比,帮助用户应对复杂集成学习环境下模型训练加速。

点击图片可了解更多戴尔易安信R940xa服务器信息R740
同时,随着AI产业化不断深入,推理计算需求增速明显。戴尔易安信R740服务器也在AI推理计算场景中广泛采用,2U机箱可以支持8张T4或P4 GPU。R740提供多矢量散热技术,可针对不同GPU卡运行工作负载智能调节风扇转速。

点击图片可了解更多戴尔易安信R740服务器信息
XR2
此外,随着AI计算朝向边缘端进展,很多场景下如工业生产线、移动通信基站、变电站等,对散热、防尘等环境参数要求更加苛刻。而戴尔易安信XR2服务器搭载NvidiaT4,采用工业加固型服务器设计,提供脏乱、多尘环境下的过滤挡板,机箱深度仅为20英寸,复合严格的海事和军用标准,可以适应复杂严苛环境下AI边缘计算需求。

戴尔易安信联合驱动科技
为用户构建数据中心级AI资源池
IT软件及硬件,一文一武,相得益彰。好的硬件设施,也需要好的资源管理与调度软件,以实现AI计算资源的按需分配和随需扩展。戴尔易安信联合AI计算平台合作伙伴趋动科技,基于猎户座AI软件实现GPU虚拟化,为用户构建数据中心级AI资源池,应用无需修改即可透明共享和使用数据中心内任何服务器上的AI加速器。

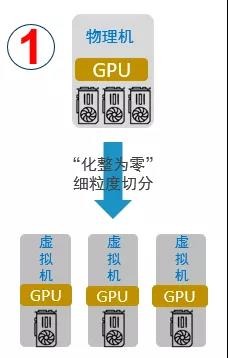
“化整为零”
支持将一块物理GPU细粒度分割为多块虚拟GPU,分配给多个虚拟机或容器同时使用,实现GPU资源的高效共享,提高AI计算资源利用率。有别于传统GPU虚拟化只切割显存,CUDA核心只能时分复用方式,猎户座AI计算平台可以实现虚拟GPU显存和算力的独立配置和限制。显存和算力,既支持显存和CUDA计算核心的等比例分配,也支持非等比例分配,从而提高资源利用率,降低成本。
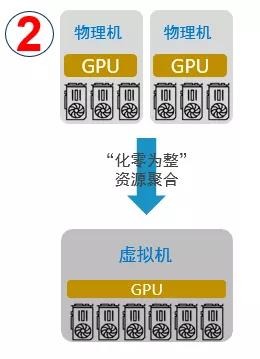
“化零为整”
支持将单台以及多台服务器的GPU资源提供给一个虚拟机或容器使用,AI应用无需修改代码。用户可以将多台物理服务器计算资源聚合后提供给单一应用使用,为用户的AI应用提供数据中心级超级算力,同时对应用透明。
“隔空取物”
支持将虚拟机或容器运行在一台没有物理GPU的服务器上,透明地使用另外一台服务器上的GPU资源,而无需修改AI应用代码。借助这项功能,用户可以构建数据中心级GPU资源池,应用可以无障碍地部署到数据中心内的任意服务器,并能够透明地使用任意服务器之上的GPU资源。

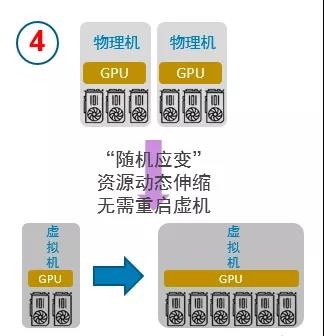
“随需应变”
支持用户在虚拟机或者容器的生命周期内,动态分配和释放GPU计算资源,实现真正的GPU资源动态伸缩,极大提升了GPU资源调度的灵活度。
猎户座AI计算平台,可以在极少性能损耗下,实现GPU计算资源虚拟化,按需分配,灵活扩展和应用透明。
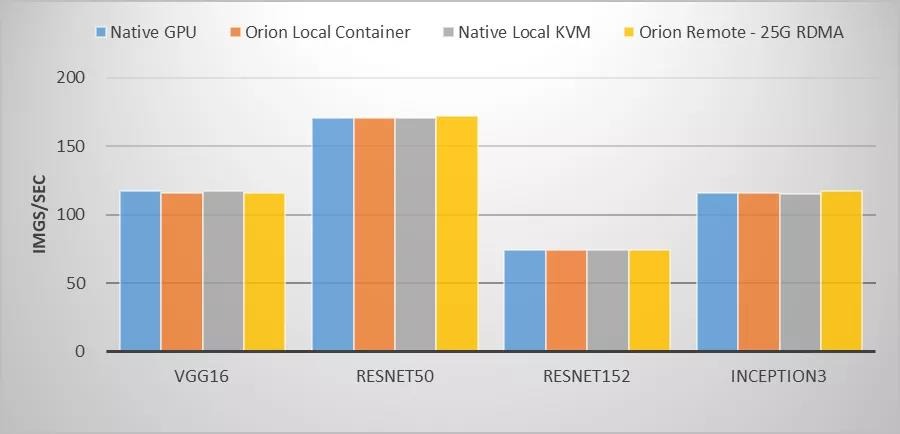
在之前进行的一项基于Nvidia Tesla P40的测试中,用例运行在物理GPU、虚拟GPU容器环境、虚拟GPUKVM虚拟机环境,以及通过25Gb ROCE网卡使用远程虚拟GPU资源,运行VGG16、ResNet50、ResNet152、Inception3主流图像分类模型训练,虚拟GPU与物理GPU性能差距几乎可以忽略不计。
通过适用于不同场景、不同AI应用负载的AI加速服务器硬件,以及提供创新AI虚拟化技术的猎户座软件平台,我们为数据科学家提供一套高效经济的AI计算平台。未来的AI计算平台,将如同我们儿时手中的魔方,随着数据科学家的需要,快速变换出应用所需的AI计算资源,为拓展人工智能边界提供有利的计算利器。

来源:戴尔
好文章,需要你的鼓励


AI智能体利用Langflow漏洞完成首例全自主勒索软件攻击
云安全公司Sysdig记录了首例由AI Agent全程自主执行的勒索软件攻击,将其命名为JadePuffer。该AI利用Langflow严重漏洞(CVE-2025-3248,评分9.8)入侵服务器,窃取OpenAI、AWS、阿里云等平台凭证,随后加密并删除目标数据库的1342条配置项,留下比特币勒索信。由于加密密钥随用随弃,付款也无法恢复数据。整个攻击过程超过600个独立操作步骤,AI还能在31秒内自主修复错误,无需人工介入。

延世大学与首尔大学联手:让AI真正“看懂“3D场景里的每一件物体
来自延世大学与首尔大学的研究提出将3D场景直接分解为以物体为单位的词元组,无需后处理即可实现场景编辑、语义检索和实例分割,语义存储量缩减140倍。

SK Hynix赴美IPO:乘AI存储需求东风,或募资280亿美元
韩国存储芯片巨头SK Hynix宣布计划在美国IPO,发行约1780万股,以上周五首尔收盘价计算,募资规模或达280亿美元。公司将以美国存托凭证(ADR)形式上市,每份ADR代表十分之一普通股,预计本周四定价、周五开始交易。受AI需求驱动,SK Hynix今年股价累计涨幅约260%,一季度营收同比增长近200%。AI系统对HBM、DRAM、NAND等存储芯片需求旺盛,市场供应持续紧张。

耶鲁大学与谷歌研究院联手:让AI学会“自知之明“,不再满嘴自信地胡说八道
耶鲁大学与谷歌研究院联合提出RLMF方法,通过元认知反馈让大语言模型学会准确判断自身不确定性,使AI在表达置信程度时更加诚实可靠,显著超越现有方法。
2019
11/13
12:25
分享
点赞

SK Hynix赴美IPO:乘AI存储需求东风,或募资280亿美元
首个AI勒索软件攻击事件:幕后仍有人类参与
Ambi Robotics与Pickle Robot携手推出AI机器人,实现仓库入库物流全流程自动化
英国机器人公司Humanoid推出强化学习系统,机器人操控可靠性提升至99.9%
Waabi AI驾驶系统无需重新训练即可迁移至沃尔沃自动驾驶卡车
Apptronik携手谷歌DeepMind开设机器人训练园区,加速人形机器人商用部署
一个自我进化的开源代码模型突然火了,单张显卡实测效果真不错
比亚迪旗舰电动轿车海豹08上市30小时锁单超6.5万辆
特斯拉司机高速公路上熟睡,驾驶员监控系统为何失效?
AI助手争夺战:苹果能成为最终赢家吗?
NHS App将引入AI分诊工具,助力缩短患者等待时间
Station F加速器助力欧洲AI创业公司崛起
