
“每日推荐”为何总能击中你的心坎?
小编每天挤上地铁后的第一件事
就是打开某云音乐,
带上耳机开始播放“每日推荐”

因为无论哪一天播放的歌都是我所喜欢的
但时间久了小编也有疑问...
原来我不是一个人!
“机器学习”这个概念太广泛了,以至于小白如我都不知道该往哪个方向挖掘。
于是,我鼓起勇气,向“高冷男神”发出了疑问。
一个小时过去了,只收到一句话个单词的回复:个性化推荐。
真棒!那小编就自力更生吧~(别问,问就是爱过)

个性化推荐
“每日推荐”里,不仅有我听过的喜欢的歌,更有我喜欢但没听过的歌。这如知己般的“每日推荐”其实就是“个性化推荐”的产物,其最基本的原理就是基于用户信息和项目信息(内容),对用户推荐其可能喜欢的音乐。

训练和推理
个性化推荐的本质是特定场景下人和信息的高效率的连接:左边是内容,右边是用户,中间通过推荐引擎连接两者。
而建立连接的方法是:利用用户和信息的特征,在两者之间进行匹配,这就是训练;建立连接的目的是为了向用户推荐可能喜欢的内容,这就是推理。

在机器学习中,“训练”模型是迭代完成的,通过加权的多层算法运行大量数据,再将其与特定目标结果进行比较,并迭代调整模型/权重,最终生成一个“训练”模型。而推理是该训练模型的成果或实时应用,是根据新数据做出相关预测的过程。
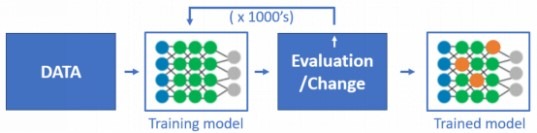
例如,在音乐类应用的推荐算法中,通常提取用户和音乐不同维度的特征值,包括音乐的标签、曲风、类型等,根据权重和关系建立模型,再通过大量数据,进行无数次的“训练”,得到一个训练好的匹配模型。
这一过程因极大的数据量和迭代次数,需要极高的计算能力。同时也需要在极短的响应时间内给出结果,所以也需要极低的延时。

训练和推理因其不同的数据处理方式,对加速器的要求也有所不同:
〓 训练工作负载需要极高的计算能力, 而推理工作负载需要更低的延时。
现如今,爆炸式的数据增长必然带来数据模型的急速增长,在高并发场景下,所有训练和推理都必须在极短的时间内完成。而且,为了提高用户体验,对训练和推理精度的要求也越来越高。对服务器的计算能力来说,这是一个很大的挑战。

? 什么样的服务器才能扛得住以上种种挑战呢?
训练和推理性能兼具,高效灵活且节能。
? 这样的“神仙”服务器是真实存在的么?

“神仙”服务器
高度灵活的戴尔易安信DSS 8440
戴尔易安信DSS 8440是一款高度灵活的服务器,旨在为训练和推理提供超高计算性能。用户可以安装4个,8个或10个NVIDIA®V100 GPU,以获得机器学习模型的高训练性能;或者安装8个,12个或16个NVIDIA®T4 GPU,带来推理性能的提高。

极致性能
V100 GPU
DSS 8440专为复杂训练工作负载而设计,可配置多达10个NVIDIA® Tesla V100 GPU,能够以高度迭代的方法快速处理多层矩阵,适用于复杂工作负载,如图像识别,面部识别和自然语言处理等。

当使用最常见的框架(如TensorFlow)和流行的卷积神经网络模型(如图像识别)时,其性能相比昂贵得多的竞品服务器相差只在5%以内。
高吞吐量
DSS 8440的低延时本地存储(STAT和NVMe-最大支持32TB)和强大吞吐能力(9个x16 IO通道)有助于快速获取机器学习的成果。
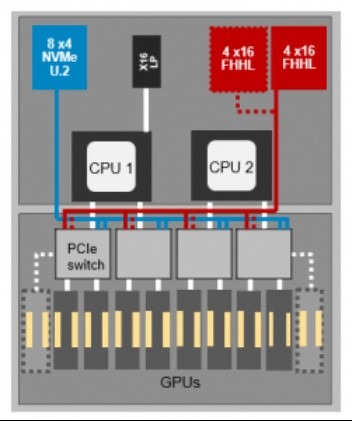
▲DSS 8440 拓扑图——可扩展至10个V100 GPU
更高功耗比
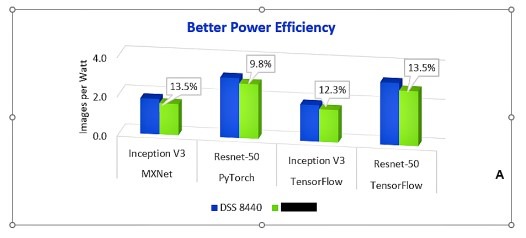
随着计算资源的增加,服务器面临的另一个挑战就是耗能。
下图可见,配置有8个V100 GPU的DSS 8440与同类竞品相比,其效率最高提升13.5%。这意味着,在执行卷积神经网络(CNN)训练进行图像识别时,在耗能相同的情况下,DSS 8440可处理更多图像。随着时间的推移,用户就可以节省大量成本。
平衡之选
T4 GPU
而配备NVIDIA® T4 GPU的DSS 8440则可提供高性能的推理能力,并带来能耗和成本的节省。用户可以选择配置8、12或16个T4 GPU作为计算资源。
虽然T4 GPU整体性能不如V100 GPU(320核 VS 640核),但足以提供出色的推理性能,而且其耗能还不到V100 GPU的30%——70瓦/GPU。

▲NVIDIAT4 Tensor Core GPU
在小批量作业中,多个T4 GPU的性能要强于单个V100 GPU,但功耗却几近相同。例如,四个T4 GPU的性能可以达到单个V100 GPU的3倍以上,但两者成本相近;两个T4 GPU的性能几乎是单个V100 GPU的两倍,但其耗能和成本却只有单个V100 GPU的一半。
低延时
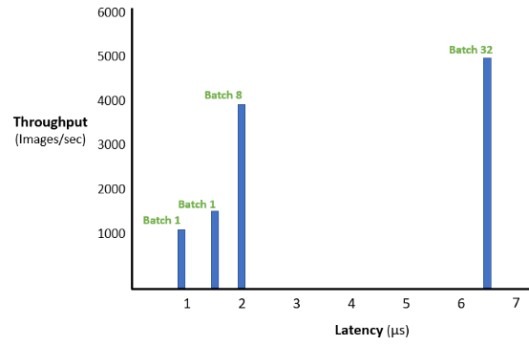
使用ResNet50模型,配置T4 GPU的DSS 8440的吞吐量为每秒平均近3900张图像,延时2.05毫秒(批处理为8)。
从下图中可以看出,批处理量为32的延时要比批处理量为8的高3倍,而吞吐量却相差很少。可见,若想同时拥有高吞吐量和低延时,批处理量为8是最佳选择。
多租户为用户带来效率和灵活性
DSS 8440是理想的多租户解决方案,它可以跨多个工作负载、多个用户或多个系统,提供机器学习训练或推理。
其灵活性使用户可以根据需要在同一服务器上同时运行不同堆栈的机器学习软件(如模型、框架和操作系统),同时使用不同数量的加速器。而且,多租户还可以使数据中心简化机器学习服务的管理。

运筹帷幄
灵活应对多种挑战
多种IO选项
数据访问对于机器学习训练至关重要。为此,DSS 8440服务器具配置了8个全高和1个半高x16PCIe插槽,适用于服务器后部。(第十个插槽保留给RAID存储控制器使用)。

大容量、高速的本地存储
同时,DSS 8440最多可配置10个存储驱动器,其中2个固定为SATA,2个固定为NVMe,另外6个可以是SATA或NVMe,从而提供了灵活的本地存储配置。

有了DSS 8440,在帮助客户应对诸多挑战的同时,还能提高效率,降低成本。无论是在线零售模式检测、医学领域症状诊断,还是深空数据分析,更强劲的计算能力能够为客户更快获得更好的结果——改善客户服务质量,帮助治愈患者,并促进研究进展。
懂你的,不止“每日推荐”。
? 还有戴尔易安信DSS 8440。
相关内容推荐:戴尔DSS:小体积释放大力量
相关产品:DELL EMC DSS 8440服务器
来源:戴尔
好文章,需要你的鼓励


首个AI勒索软件攻击事件:幕后仍有人类参与
云安全公司Sysdig记录了首个"代理式勒索软件"案例——JadePuffer行动。AI代理自主完成入侵服务器、窃取凭证、加密文件并生成勒索信等全流程操作,速度惊人。然而,该攻击并非完全无人介入:人类仍负责选定目标、部署基础设施并提供初始访问凭证。研究人员暂未确认驱动该代理的具体模型,但指出随着运行成本降低,类似攻击规模可能快速扩大。

卫星地图也能“按图索骥“?圣路易斯华盛顿大学研发出能读懂地图符号的AI图像生成系统
TerraDiT-Ω是圣路易斯华盛顿大学研发的卫星图像生成系统,能直接读取多边形、折线等地图原生符号生成高保真卫星图像,标注越精细效果越好。

英国机器人公司Humanoid推出强化学习系统,机器人操控可靠性提升至99.9%
英国机器人与AI公司Humanoid发布KinetIQ Ascend强化学习系统,目标是以人类速度甚至更快达到99.9%的操作可靠性。该系统通过试错学习,在多项工业任务中表现出色:在机器送料任务中吞吐量提升42%,拣货递物任务成功率从80%升至98%,双臂搬运任务成功率达99%,且所有成果仅需数天训练即可实现。该系统还展示出类似大语言模型的扩展规律,训练时间越长性能越稳定提升。

天津大学与上海人工智能实验室联手:让AI同时“读懂“和“模拟“人类大脑的视觉思维
BrainJanus是由天津大学与上海人工智能实验室联合提出的统一大脑模型,首次在单一自回归框架内实现大脑信号与图像、语言的双向任意转换,并揭示了大脑编码语义级评估的系统性漏洞。
2019
12/30
12:00
分享
点赞

英国机器人公司Humanoid推出强化学习系统,机器人操控可靠性提升至99.9%
Waabi AI驾驶系统无需重新训练即可迁移至沃尔沃自动驾驶卡车
Apptronik携手谷歌DeepMind开设机器人训练园区,加速人形机器人商用部署
一个自我进化的开源代码模型突然火了,单张显卡实测效果真不错
比亚迪旗舰电动轿车海豹08上市30小时锁单超6.5万辆
特斯拉司机高速公路上熟睡,驾驶员监控系统为何失效?
AI助手争夺战:苹果能成为最终赢家吗?
NHS App将引入AI分诊工具,助力缩短患者等待时间
Station F加速器助力欧洲AI创业公司崛起
橡树岭国家实验室与克利夫兰诊所联合模拟聚变反应堆材料化学
Even Realities完成1.5亿美元融资,估值达10亿美元
数据中心会造成空气污染吗?关键在于电力来源
