
全球IT圈票选存储领域最佳品牌企业
★喜报★
近日,提供数据中心架构
相关数据与分析的网站IT Brand Pulse
公布了2020年存储品牌领导者报告
报告中
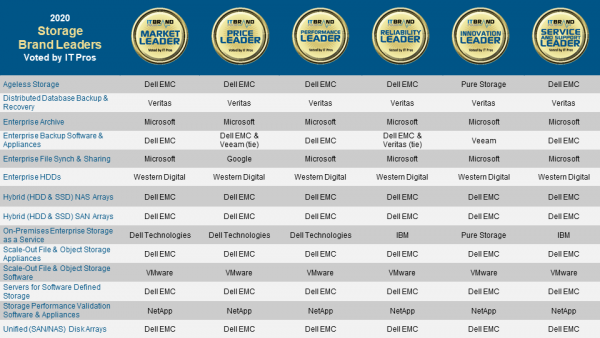
戴尔科技集团在共计14个类别的存储中
赢得了9项类别的领导者!

感谢广大用户对戴尔科技的信任与厚爱!
注:文末可见完整榜单
关于IT Brand Pulse2020年存储品牌领导者报告
![]()
IT Brand Pulse将存储划分为企业备份软件和设备、混合NAS阵列等14个类别,每个类别按照行业领导者、价格领导者、性能领导者、可靠性领导者、服务和支持领导者以及创新领导者共6个维度进行评分,并通过无赞助调查方式收集世界各地IT专业人员给与的反馈,意图展现该品牌在客户心中的全貌。
本次存储领导者的评选,充分体现了戴尔科技广泛而全面产品家族下领先产品的产品实力,9项领导者的获得不仅包括戴尔易安信,也包括了VMware。
戴尔易安信获得的领导者奖项
☆ 永恒存储(Ageless Storage)
☆ 企业备份软件和设备
☆ 混合NAS阵列
☆ 混合SAN阵列
☆ 企业本地存储即服务
☆ 统一SAN/NAS阵列
☆ 横向扩展文件和对象存储设备
☆ 用于软件定义存储的服务器
VMware获得的领导者奖项
☆ 横向扩展文件和对象存储软件
▼在这里,我们对一些重点奖项进行介绍▼
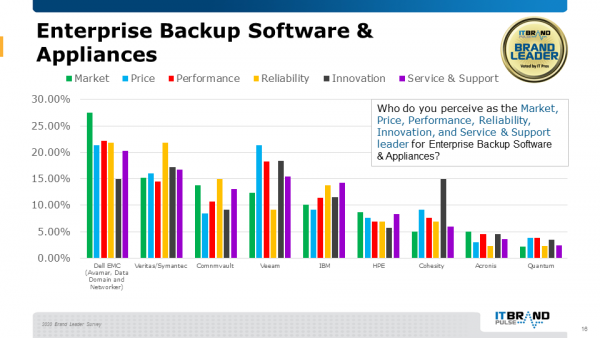
01企业备份软件和设备行业领导者
这是IT专业人员连续三年选择戴尔易安信作为企业备份软件和设备行业领导者,以及性能、服务和支持的领导者。
代表产品
PowerProtect DD系列
Data Protection Suite
? PowerProtect DD是业界首屈一指的保护存储,其在业内拥有近20年的历史,不仅久经验证,也是全球众多用户的首选。在今天的虚拟化环境中,PowerProtect DD的消重比平均可到55:1甚至更高。

?戴尔易安信Data Protection Suite包含Avamar、NetWorker、Data Protection Advisor的三个主要软件,覆盖了复制、快照、数据备份与操作恢复、归档、灾难恢复等功能,在为用户提供个性化数据保护选择的同时,为本地传统基础设施到虚拟化环境(包括公有云和混合云)中的数据和应用程序提供同等极佳的保护。

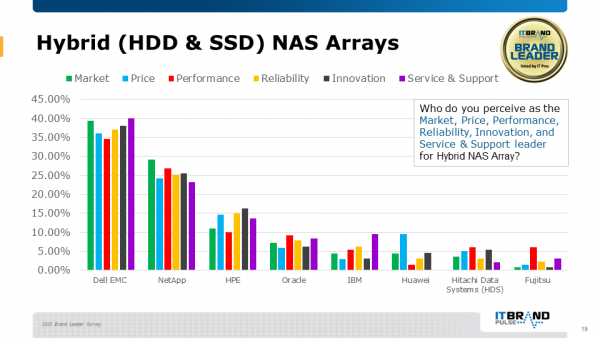
02混合NAS阵列领导者
戴尔易安信已连续第二年获选混合NAS阵列的行业、价格、性能、可靠性、创新以及服务和支持的领导者,并且相比其他品牌有着明显优势。
代表产品
Isilon横向扩展NAS存储
2019年第71届技术工程艾美奖颁给了它,以表彰其在HSM(分层存储管理)系统的早期开发,为广播工作流程改进做出杰出的贡献。
夺得中国影史票房第二位的电影《哪吒》也和它有关,其所有数字化特效和后期渲染剪辑,都是在Isilon上完成!更不用说自Gartner发布第一份分布式文件系统和对象存储魔力象限以来,连续4年在领导者象限遥遥领先的都是它。

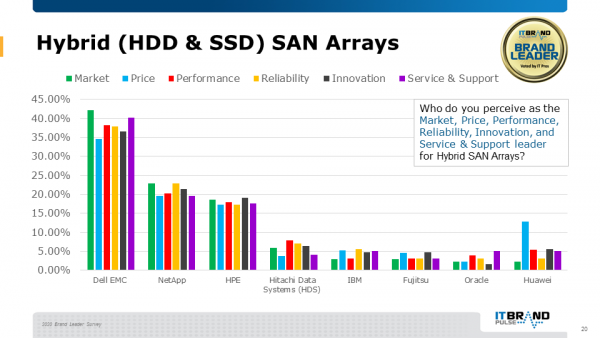
03混合SAN阵列领导者
戴尔易安信继续成为混合SAN阵列的行业领导者,这一奖项已是连续第八次获得,同时戴尔易安信在价格、性能、可靠性、创新以及服务和支持方面居于领先地位。
代表产品
戴尔易安信SC存储
戴尔易安信SC存储的前身是大名鼎鼎的Compellent存储。目前,戴尔易安信SC存储系列提供了多种选项,包括从适合中小企业的入门级智能存储SC v2000,到适合中等规模企业部署的SC4020、SC5020,再到适合大型综合业务处理的SC7020,直至超大规模业务支撑平台SC9000,覆盖了所有规模的企业和应用场景。
其特点之一是标配的联邦存储功能,可将新老几代存储进行有效聚合,打造云存储资源池,均衡各存储工作负载。

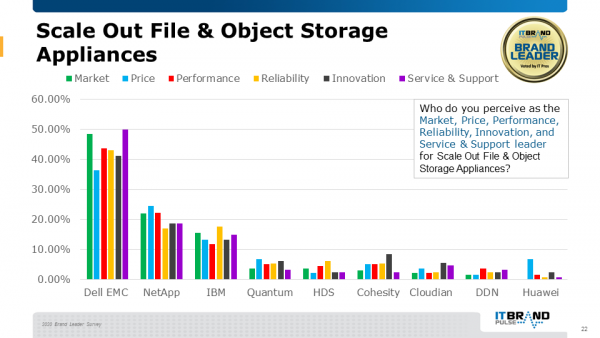
04横向扩展文件和对象存储设备领导者

IT专业人员重复了去年的投票,使得戴尔易安信再次位居横向扩展文件和对象存储设备的领导者位置。并在行业、价格、性能、可靠性、创新以及服务和支持方面遥遥领先。
代表产品
Isilon横向扩展NAS存储
同上。
05统一SAN/NAS磁盘阵列
这是戴尔易安信连续第二年蝉联统一磁盘阵列的全部六个领导者头衔。
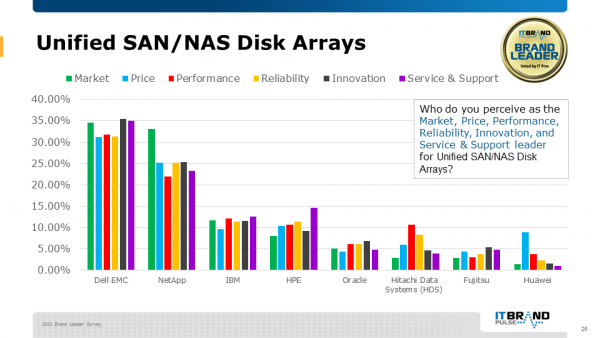
代表产品
Unity XT系列
? 戴尔易安信Unity XT系列凭借卓著的简便性、全包式软件、超快的速度、优化的效率和多云支持,为存储设定了新标准。非常适合支持要求苛刻的虚拟化应用程序、部署统一存储和满足远程办公室的要求。

再次感谢所有客户将你们宝贵的一票投给了我们,感谢你们始终信任,把最宝贵的资产数据交给我们存储、分析和保护。我们将继续提供优质可靠的产品,不断满足您的业务需求,助力您的数字化转型走向成功!
▼附完整榜单▼
《从“女孩”到“妈妈”》中奖名单
请中奖的小伙伴在五个工作日之内,把联系方式(姓名+手机号+奖品寄送地址)发给我们,逾期作废,抓紧来领奖哦。
来源:戴尔
好文章,需要你的鼓励


Albertsons借助Databricks构建零售商品智能决策平台
美国连锁超市巨头Albertsons正在基于Databricks构建商品智能平台,整合产品、定价、促销与陈列等决策功能,目标是在2026年底前全面向门店运营商落地。该平台以Databricks Lakehouse存储零售数据,通过Unity Catalog与AI Gateway实现数据治理,并借助AI智能体Genie支持自然语言查询,帮助商家洞察销售趋势,提升决策效率。此举是Albertsons今年四项AI核心战略投资之一。

阿里巴巴让AI图像生成模型“自我进化“:Qwen-Image-2.0-RL是如何让机器学会审美的?
阿里Qwen团队通过引入强化学习和在线策略蒸馏,将Qwen-Image-2.0升级为Qwen-Image-2.0-RL,让图像生成模型真正学会人类审美,文生图Elo评分提升78分,图像编辑提升93分。

微软正式将 Windows 11 打造为 AI 操作系统
微软正将Windows 11打造成真正的AI操作系统。在Build大会上,微软展示了AI模型与智能代理如何深度融合进Windows 11,让用户通过自然语言完成系统操作。借助Windows ML框架,超过5亿台PC已可在本地离线运行AI任务,无需联网、无token费用、数据不离设备。Office、Photos、Teams等应用已支持本地AI能力,Adobe、WhatsApp、Canva等第三方也在积极跟进,企业级AI PC采购需求有望加速。

港科大联手快手,让AI画图“减减肥“:一个让图像生成更真实的小技巧
港科大与快手联合提出NormGuard,针对流匹配模型强化学习训练中速度范数膨胀问题,通过训练时单向惩罚约束,在保留奖励的同时改善图像真实感。
2020
05/13
16:43
分享
点赞

Albertsons借助Databricks构建零售商品智能决策平台
微软正式将 Windows 11 打造为 AI 操作系统
工作中使用未授权AI工具之前,请三思
全球首座AI博物馆Dataland:用数据创造多感官视觉盛宴
ANS框架:Linux基金会为AI智能体建立DNS式信任机制
Hirebotics推出无代码防爆协作机器人,专为工业喷涂设计
美国消费品安全委员会拟出台电动自行车电池安全新规
江波龙:建设完成mSSD月产能百万交付能力!mSSD高速存储介质赋能端侧AI规模应用
从IO500双榜第一,看国产存储的系统级突破
Rocket Lab宣布以80亿美元收购卫星运营商铱星公司
OpenAI携手Trail of Bits发起"Patch the Planet"开源安全修复计划
公共电力性价比优势面临多年来最严峻考验
